Erste Schritte mit einem hochverfügbaren ODH Big Data-Cluster
Mit einem Oracle Cloud Infrastructure-Account können Sie ein hochverfügbares Big Data-Cluster mit Oracle-Distribution einschließlich Apache Hadoop erstellen.
Zum Erstellen von Big Data-Clustern können Sie Optionen für Knotenausprägungen und Speichergrößen verwenden. Wählen Sie diese Optionen je nach Anwendungsfall und Performanceanforderungen aus. In diesem Workshop erstellen Sie ein HA-Cluster und weisen den Knoten kleine Ausprägungen zu. Dieses Cluster eignet sich ideal zum Testen von Anwendungen.
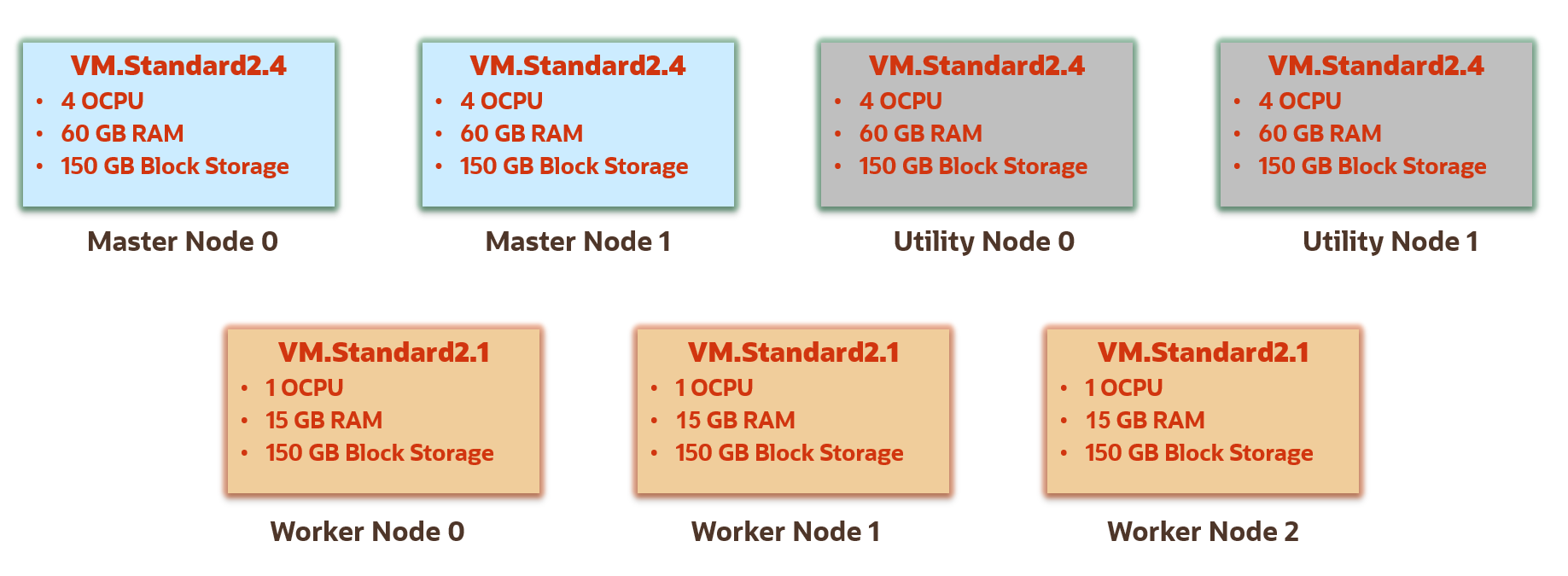
Dieses einfache HA-Cluster hat das folgende Profil:
-
Knoten: 2 Masterknoten, 2 Utilityknoten und 3 Worker-Knoten.
-
Ausprägung der Haupt- und Utilityknoten: VM.Standard2.4-Ausprägung für die Master- und Utilityknoten. Diese Ausprägung bietet 4 CPUs und 60 GB Arbeitsspeicher.
-
Ausprägung der Worker-Knoten: VM.Standard2.1-Ausprägung für die Worker-Knoten im Cluster. Diese Ausprägung bietet 1 CPU und 15 GB Arbeitsspeicher.
-
Speichergröße: 150 GB Blockspeicher für die Master-, Utility- und Worker-Knoten.
Bevor Sie beginnen
Für eine erfolgreiche Ausführung des Tutorials benötigen Sie Folgendes:
- Oracle Cloud Infrastructure-Account Siehe Für Oracle Cloud Infrastructure registrieren.
- Ein MacOS-, Linux- oder Windows-Computer mit installierter
ssh-Unterstützung.
Übung 1. Für Big Data-Cluster erforderliche OCI-Ressourcen einrichten
In dieser Übung verwenden Sie einen Oracle Cloud Infrastructure-Account, um die zum Erstellen eines Big Data-Clusters erforderlichen Ressourcen vorzubereiten.
- Anmelden bei der Oracle Cloud Infrastructure-Konsole.
- Öffnen Sie das Navigationsmenü, und wählen Sie Governance und Administration aus. Wählen Sie unter Governance die Option Limits, Quota und Nutzung aus.
- Ermitteln Sie Ihr Servicelimit für Big Data-Knotenausprägungen:
-
Filter für die folgenden Optionen:
- Service: Big Data
-
Geltungsbereich:
<your-region>(entspricht der Region in der oberen Navigationsleiste) -
Ressource:
-
VM Standard2.4 - OCPUs gesamt(für Master-, Utility- und Cloud SQL-Knoten) -
VM Standard2.1 - OCPUs gesamt(für Worker-Knoten)
-
-
Compartment:
<tenancy-name>(Root)
- verfügbare OCPU-Anzahl suchen:
-
Limitname:
vm-standard-2-4-ocpu-count -
Verfügbar:
- Für nicht hochverfügbare (Nicht-HA-)Cluster: mindestens 3
(Eine für den Masterknoten, eine für den Utilityknoten und eine für Cloud SQL.)
- Für hochverfügbare (HA-)Cluster: mindestens 5
(Zwei für Masterknoten, zwei für Utilityknoten und eine für Cloud SQL.)
- Für nicht hochverfügbare (Nicht-HA-)Cluster: mindestens 3
-
Limitname:
vm-standard-2-1-ocpu-count - Verfügbar: Mindestens 3
-
Limitname:
-
Filter für die folgenden Optionen:
In diesem Workshop erstellen Sie Knoten mit folgenden Ausprägungen und folgendem Speicher:
Ausprägung:
- VM Standard2.4 für die Master-, Utility- und Cloud SQL-Knoten.
- VM Standard2.1 für die Worker-Knoten.
Speicher:
- 150 GB Blockspeicher für die Master-, Utility- und Worker-Knoten.
- 1.000 GB Blockspeicher für den Cloud SQL-Knoten.
Wenn Sie eine andere Ausprägung verwenden möchten, filtern Sie stattdessen nach dieser Ausprägung. Eine Liste aller in Big Data Service unterstützten Ausprägungen finden Sie unter Servicelimits.
Erstellen Sie ssh-Verschlüsselungsschlüssel, um eine Verbindung zu Ihren Compute-Instanzen oder Knoten herzustellen.
Weitere Informationen zum Generieren von SSH-Verschlüsselungsschlüsseln finden Sie unter Schlüsselpaar erstellen.
In diesem Workshop werden keine PuTTY-Schlüssel verwendet. Erstellen Sie Ihr Schlüsselpaar anhand der Anweisungen in diesem Abschnitt.
Wenn sich Ihr Benutzername in der Gruppe Administratoren befindet, überspringen Sie diesen Abschnitt. Andernfalls muss der Administrator Ihrem Mandanten die folgende Policy hinzufügen:
allow group <the-group-your-username-belongs> to manage compartments in tenancyMit dieser Berechtigung können Sie ein Compartment für alle Ressourcen in Ihrem Tutorial erstellen.
- Öffnen Sie in der oberen Navigationsleiste das Menü Profil.
- Wählen Sie Ihren Benutzernamen aus.
- Klicken Sie im linken Fensterbereich auf Gruppen.
- Kopieren Sie den Gruppennamen, zu der Ihr Benutzername gehört, in einem Notizblock.
- öffnen Sie das Navigationsmenü, und wählen Sie Identität und Sicherheit aus. Wählen Sie unter Identität die Option Policys aus.
- Wählen Sie Ihr Compartment in der Dropdown-Liste Compartment aus.
- Wählen Sie Policy erstellen aus.
- Geben Sie die folgenden Informationen ein:
-
Name:
manage-compartments -
Beschreibung:
Allow the group <the-group-your-username-belongs> to list, create, update, delete and recover compartments in the tenancy. -
Compartment:
<your-tenancy>(root)
-
Name:
- Klicken Sie unter Policy Builder auf Anpassen (erweitert).
- Fügen Sie die folgende Policy ein:
allow group <the-group-your-username-belongs> to manage compartments in tenancy - Wählen Sie Erstellen.
Referenz: Der Ressourcentyp compartments in Kombinationen aus Verben + Ressourcentyp für IAM
Erstellen Sie ein Compartment für die Ressourcen, die Sie in diesem Tutorial erstellen.
- Anmelden bei der Oracle Cloud Infrastructure-Konsole.
- öffnen Sie das Navigationsmenü, und wählen Sie Identität und Sicherheit aus. Wählen Sie unter Identität die Option Compartments aus.
- Compartment erstellen.
- Geben Sie die folgenden Informationen ein:
-
Name:
<your-compartment-name>.Beispiel:
training-compartment. -
Beschreibung:
Compartment for <your-description>. -
Übergeordnetes Compartment:
<your-tenancy>(root)
-
Name:
- Compartment erstellen.
Wenn sich Ihr Benutzername in der Gruppe Administratoren befindet, überspringen Sie diesen Abschnitt. Andernfalls muss der Administrator Ihrem Compartment die folgende Policy hinzufügen:
allow group <the-group-your-username-belongs> to manage all-resources in compartment <your-compartment-name>
Mit dieser Berechtigung können Sie alle Ressourcen in Ihrem Compartment verwalten, das Ihnen im Wesentlichen Administratorrechte in dem Compartment erteilt.
- öffnen Sie das Navigationsmenü, und wählen Sie Identität und Sicherheit aus. Wählen Sie unter Identität die Option Policys aus.
- Wählen Sie Ihr Compartment in der Dropdown-Liste Compartment aus.
- Policy erstellen.
- Geben Sie die folgenden Informationen ein:
-
Name:
manage-<your-compartment-name>-resources -
Beschreibung:
Allow users to list, create, update, and delete resources in <your-compartment-name>. -
Compartment:
<your-compartment-name>
-
Name:
- Wählen Sie unter Policy Builder die folgenden Optionen aus:
-
Policy-Anwendungsfälle:
Compartment Management -
Allgemeine Policy-Vorlagen:
Let compartment admins manage the compartment -
Gruppen:
<the-group-your-username-belongs> -
Speicherort:
<your-compartment-name>
-
Policy-Anwendungsfälle:
- Erstellen.
Referenz: Allgemeine Policys
Big Data Service kann ein virtuelles Cloud-Netzwerk in Ihrem Mandanten nur erstellen, wenn Sie ihm die entsprechende Berechtigung erteilen. Fügen Sie dem Compartment die folgende Policy hinzu:
allow service bdsprod to {VNC_READ, VNIC_READ, VNIC_ATTACH, VNIC_DETACH, VNIC_CREATE, VNIC_DELETE,VNIC_ATTACHMENT_READ, SUBNET_READ, VCN_READ, SUBNET_ATTACH, SUBNET_DETACH, INSTANCE_ATTACH_SECONDARY_VNIC, INSTANCE_DETACH_SECONDARY_VNIC} in compartment <your-compartment-name>Mit dieser Berechtigung kann Big Data die Netzwerkressourcen erstellen in Ihrem Compartment.
- öffnen Sie das Navigationsmenü, und wählen Sie Identität und Sicherheit aus. Wählen Sie unter Identität die Option Policys aus.
- Wählen Sie im Dropdown-Menü Compartment Ihr Compartment aus.
- Wählen Sie Policy erstellen aus.
- Geben Sie die folgenden Informationen ein:
-
Name:
big-data-create-network-resources -
Beschreibung:
Allow Big Data service to create a virtual cloud network. -
Compartment:
<your-compartment-name>
-
Name:
- Aktivieren Sie unter Policy Builder die Option Manuellen Editor anzeigen.
- Fügen Sie die folgende Policy im Editor ein:
allow service bdsprod to {VNC_READ, VNIC_READ, VNIC_ATTACH, VNIC_DETACH, VNIC_CREATE, VNIC_DELETE,VNIC_ATTACHMENT_READ, SUBNET_READ, VCN_READ, SUBNET_ATTACH, SUBNET_DETACH, INSTANCE_ATTACH_SECONDARY_VNIC, INSTANCE_DETACH_SECONDARY_VNIC} in compartment <your-compartment-name> - Wählen Sie Erstellen.
Achten Sie darauf, diese Policy zu erstellen. Ohne diese Policy können Sie kein Cluster erstellen.
Richten Sie ein virtuelles Cloud-Netzwerk zum Hosten der Knoten in Ihrem Cluster ein.
-
Gehen Sie zu Ressourcen starten, und klicken Sie in der Haupt-Landingpage der Konsole auf Netzwerk über einen Assistenten einrichten.
Um mit ssh auf die Knoten zuzugreifen, öffnet der Assistent VCN starten automatisch Port 22 in Ihrem öffentlichen Subnetz. Um andere Ports zu öffnen, müssen Sie der Sicherheitsliste Ihres VCN Ingress-Regeln hinzufügen.
In diesem Abschnitt fügen Sie dem öffentlichen Subnetz eine Ingress-Regel hinzu, um den Zugriff auf Apache Ambari zu ermöglichen.
Übung 2. Hochverfügbares ODH-Cluster erstellen
Erstellen Sie ein HA-Cluster, und überwachen Sie die Schritte.
Wenn Sie diesen Workshop mit einem kostenlosen Testaccount ausführen, empfiehlt Oracle, das BDS-Cluster nach Abschluss des Workshops zu löschen, um unnötige Gebühren zu vermeiden.
Die training-cluster ist ein hochverfügbares (HA-)Cluster. In allen ODH-HA-Clustern sind die Services wie folgt verteilt:
| Masterknoten | Utilityknoten |
Worker-Knoten, traininwn0, traininwn1, traininwn2
|
|---|---|---|
Erster Masterknoten traininmn0
traininmn1
|
Erster Utilityknoten traininun0
traininun1
|
|
Die Erstellung des Clusters dauert etwa eine Stunde. Sie können den Fortschritt der Clustererstellung wie folgt überwachen:
Übung 3. Oracle Cloud SQL zum Cluster hinzufügen
Sie fügen Oracle Cloud SQL zu einem Cluster hinzu, damit Sie Ihre Big Data-Quellen mit SQL abfragen können. Wenn Sie Cloud SQL-Unterstützung zu einem Cluster hinzufügen, wird ein Abfrageserverknoten hinzugefügt, und Big-Data-Cell-Server werden auf allen Worker-Knoten erstellt.
Cloud SQL ist nicht in Big Data Service enthalten. Für die Verwendung von Cloud SQL müssen Sie eine zusätzliche Gebühr bezahlen.
-
Klicken sie auf der Seite Cluster in der Zeile für
training-clusterauf die Schaltfläche Aktionen. - Wählen Sie im Kontextmenü die Option Cloud SQL hinzufügen aus.
-
Im Dialogfeld Cloud SQL hinzufügen geben Sie die folgenden Informationen an:
-
Ausprägung des Abfrageserverknoters: Wählen Sie
VM.Standard2.4aus. -
Blockspeicher des Abfrageserverknoters (in GB): Geben Sie
1000ein. -
Admin-Kennwort des Clusters: Geben Sie das Clusteradministrationskennwort ein, das Sie beim Erstellen des Clusters gewählt haben. Beispiel:
Training123.
-
Ausprägung des Abfrageserverknoters: Wählen Sie
-
Hinzufügen. Die Seite Cluster wird erneut angezeigt. Der Status von
training-clusterlautet jetzt Wird aktualisiert, und die Anzahl der Knoten im Cluster wird um 1 erhöht. -
Klicken Sie in die Spalte Name auf den Namenslink training-cluster, um die Seite Clusterdetails anzuzeigen. Scrollen Sie nach unten zum Abschnitt Liste der Clusterknoten. Der neu hinzugefügte Cloud SQL-Knoten
traininqs0wird angezeigt. - die Registerkarte Cloud SQL-Informationen, um Informationen zum neuen Cloud SQL-Knoten anzuzeigen.
-
Arbeitsanforderungen im Abschnitt Ressourcen. Im Abschnitt Arbeitsanforderungen wird der Vorgang
ADD_CLOUD_SQLzusammen mit dem Status des Vorgangs und dem Status in Prozent angezeigt. Der LinkADD_CLOUD_SQL. - Auf der Seite Arbeitsanforderungsdetails werden Status, Logs und Fehler (falls vorhanden) beim Hinzufügen des Cloud SQL-Knotens zum Cluster angezeigt.
- Über den Link Cluster oben in den Navigationspfaden können Sie die Seite Cluster erneut anzeigen. Sobald der Cloud SQL-Knoten erfolgreich zum Cluster hinzugefügt worden ist, ändert sich der Status der Cluster in Aktiv, und die Anzahl der Knoten im Cluster ist jetzt um 1 erhöht.
Übung 4. Private IP-Adressen öffentlichen IP-Adressen zuordnen
Big Data Service-Knoten werden standardmäßig private IP-Adressen zugewiesen, die über das öffentliche Internet nicht zugänglich sind.
VPN Connect und OCI FastConnect stellen mit einem Bastionhost Optionen bereit, die mehr Privatsphäre und Sicherheit bieten als die Offenlegung der IP-Adresse.
In dieser Übung verwenden Sie Oracle Cloud Infrastructure Cloud Shell, ein browserbasiertes Terminal, auf das von der Oracle Cloud-Konsole aus zugegriffen werden kann.
- Öffnen Sie das Navigationsmenü, und wählen Sie Analysen und KI aus. Wählen Sie unter Data Lake die Option Big Data Service aus.
-
Klicken Sie auf der Seite Cluster in der Spalte Name auf den Link
training-cluster, um die Seite Clusterdetails anzuzeigen. - Klicken Sie in der Registerkarte Clusterinformationen im Abschnitt Informationen zum Kundennetzwerk neben Subnetz-OCID auf den Link Kopieren. Fügen Sie diese OCID in einen Editor oder eine Datei ein. Sie benötigen sie später in diesem Workshop.
-
Suchen Sie auf derselben Seite im Abschnitt Liste der Clusterknoten in der Spalte IP-Adresse die privaten IP-Adressen für den Utilityknoten
traininun0, den Masterknotentraininmn0und den Cloud SQL-Knotentraininqs0. Speichern Sie die IP-Adressen. Sie benötigen sie bei nachfolgenden Aufgaben erneut.
Ein Utilityknoten enthält in der Regel Utilitys für den Zugriff auf das Cluster. Wenn Sie die Utilityknoten im Cluster öffentlich verfügbar machen, werden die auf den Utilityknoten ausgeführten Services im Internet verfügbar.
export drei Variablen festgelegt. Diese Variablen werden im Befehl oci network verwendet, mit denen Sie die private IP-Adresse des Utilityknotens einer neuen öffentlichen IP-Adresse zuordnen.-
Klicken Sie oben auf der Seite im Banner der Oracle Cloud-Konsole auf Cloud Shell
 . Das Herstellen der Verbindung und Ihre Authentifizierung kann etwas Zeit in Anspruch nehmen.
Um das Farb-Thema des Cloud Shell-Hintergrunds von dunkel in hell zu ändern, klicken Sie im Cloud Shell-Banner auf Einstellungen
. Das Herstellen der Verbindung und Ihre Authentifizierung kann etwas Zeit in Anspruch nehmen.
Um das Farb-Thema des Cloud Shell-Hintergrunds von dunkel in hell zu ändern, klicken Sie im Cloud Shell-Banner auf Einstellungen , und wählen Sie im Menü Einstellungen die Option "Theme > Hell" aus.
, und wählen Sie im Menü Einstellungen die Option "Theme > Hell" aus.
In dieser Aufgabe legen Sie mit dem Befehl export zwei Variablen festgelegt. Diese Variablen werden im Befehl oci network verwendet, mit denen Sie die private IP-Adresse des Masterknotens einer neuen öffentlichen IP-Adresse zuordnen. In der vorherigen Aufgabe haben Sie einen ähnlichen Schritt ausgeführt.
In dieser Aufgabe legen Sie mit dem Befehl export zwei Variablen festgelegt. Als Nächstes ordnen Sie mit dem Befehl oci network die private IP-Adresse des Cloud SQL-Knotens einer neuen öffentlichen IP-Adresse zu.
In dieser Aufgabe bearbeiten Sie eine öffentliche IP-Adresse sowohl mit der Cloud-Konsole als auch mit der Cloud Shell.
Sie können öffentliche IP-Adressen auch mit der OCI-CLI bearbeiten. Siehe OCI-CLI-Befehlsreferenz - public-ip.
Löschen Sie keine Ihrer öffentlichen IP-Adressen, denn Sie benötigen sie für dieses Tutorial.
Übung 5. Mit Apache Ambari auf das Cluster zugreifen
In dieser Aufgabe verwenden Sie Apache Ambari für den Zugriff auf das Cluster. In einem Big Data-Cluster wird der Apache Ambari auf dem ersten Utilityknoten, traininun0 , ausgeführt. Sie verwenden die reservierte öffentliche IP-Adresse, die mit traininun0 verknüpft ist, die Sie in Aufgabe 2 von Übung 4 erstellt haben.
Übung 6. Hadoop-Administratorbenutzer erstellen
In dieser Aufgabe stellen Sie eine Verbindung zum Masterknoten des Clusters her, indem Sie SSH als Benutzer opc (Standardbenutzer von "Oracle Public Cloud") verwenden.
Bei Erstellen eines Clusters haben Sie den SSH-Public Key verwendet, um die Knoten zu erstellen. In diesem Abschnitt verwenden Sie den entsprechenden Private Key, um eine Verbindung zum Masterknoten herzustellen.
Erstellen Sie den Linux-Administratorbenutzer training und die BS-Gruppe supergroup . Weisen Sie training die Superuser-Gruppe supergroup als primäre Gruppe und hdfs, hadoop und hive als sekundäre Gruppen zu.
In diesem Schritt erstellen Sie einen neuen Kerberos-Principal mit dem Namen training . Identitäten in Kerberos werden als Principals bezeichnet. Jeder Benutzer und Service, der das Kerberos-Authentifizierungsprotokoll verwendet, benötigt einen Principal, um sich eindeutig zu identifizieren. Es gibt Benutzer-Principals und Service-Principals. Benutzer-Principal-Namen oder UPNs stellen normale Benutzer wie training dar.
Melden Sie sich bei einer der Big Data Service-Knoten an und wie dem ersten Masterknoten, rufen Sie ein Kerberos-Ticket für den Benutzer training ab, und führen Sie eine Dateiauflistung von HDFS durch.
Übung 7. Daten in HDFS und Object Storage hochladen
In diesem Schritt laden Sie zwei Skripte herunter und führen sie aus.
Erstens laden Sie die Hadoop Distributed File System-(HDFS-)Skripte herunter und führen sie aus, um Daten von Citi Bikes NYC in ein neues lokales Verzeichnis auf Ihrem Masterknoten in Ihrem BDS-Cluster herunterzuladen. Die HDFS-Skripte bearbeiten einige der heruntergeladenen Datendateien und laden sie dann in neue HDFS-Verzeichnisse hoch. Die HDFS-Skripte erstellen auch Hive-Datenbanken und -Tabellen, die Sie mit Hue abfragen.
Zweitens laden Sie die Objektspeicherskripte herunter und führen sie aus, um Daten von Citi Bikes NYC mit OCI Cloud Shell in Ihr lokales Verzeichnis herunterzuladen. Die Objektspeicherskripte laden die Daten in einen neuen Bucket in Object Storage hoch. Informationen zum Citi Bikes NYC-Datenlizenzvertrag finden Sie unter Datenlizenzvertrag.
- Öffnen Sie das Navigationsmenü, und wählen Sie Identität und Sicherheit aus. Wählen Sie unter Identität die Option Compartments aus.
- Suchen Sie in der Liste der Compartments nach dem training-compartment. In der Zeile für das Compartment bewegen Sie in der Spalte OCID den Mauszeiger über den OCID-Link, und klicken Sie dann auf Kopieren. Fügen Sie diese OCID in einen Editor oder eine Datei ein, damit Sie sie später in diesem Schritt abrufen können.
- Navigieren Sie im Menü Navigation zu Networking > Reservierte IPs. Die Seite Reservierte öffentliche IP-Adressen wird angezeigt. Stellen Sie sicher, dass im Listengeltungsbereich im linken Fensterbereich das training-compartment ausgewählt ist.
-
Kopieren Sie die reservierte öffentliche IP-Adresse in der Zeile für die reservierte IP-Adresse
traininmn0-public-ip, die mit dem Masterknoten verknüpft ist, in der Spalte Reservierte öffentliche IP. Fügen Sie diese IP-Adresse in einen Editor oder in eine Datei ein, damit Sie sie später in diesem Schritt abrufen können. Falls Sie Ihre SSH-Verbindung in Schritt 5 nicht gespeichert haben, benötigen Sie diese IP-Adresse für die SSH-Verbindung mit dem Masterknoten.
In dieser Aufgabe stellen Sie mit SSH als Hadoop-Administratorbenutzer training eine Verbindung zum Masterknoten in dem Cluster, den Sie in Schritt 5 erstellt haben.
In dieser Aufgabe stellen Sie als Benutzer training, den Sie in Schritt 5: Hadoop-Administratorbenutzer erstellen erstellt haben, eine Verbindung zu dem Masterknoten ein.
In dieser Aufgabe laden Sie zwei Skripte herunter, die Ihre HDFS-Umgebung einrichten und das HDFS-Dataset aus Citibike System Data herunterladen. Die Skripte und eine randomisierte Wetterdatendatei werden in einem öffentlichen Bucket in Object Storage gespeichert.
Die Citi Bikes-Datendateien mit Fahrtdetails (in komprimiertem Format) werden zuerst in ein neues lokales Verzeichnis heruntergeladen. Anschließend werden die Dateien dekomprimiert, und die Headerzeile wird aus jeder Datei entfernt. Schließlich werden die aktualisierten Dateien in ein neues HDFS-Verzeichnis /data/biketrips hochgeladen. Als Nächstes wird eine neue Hive-Datenbank bikes mit zwei Hive-Tabellen erstellt. bikes.trips_ext ist eine externe Tabelle, die über die Quelldaten definiert wird. Die Tabelle bikes.trips wird aus dieser Quelle erstellt. Dabei handelt es sich um eine partitionierte Tabelle, in der die Daten im Parquet-Format gespeichert sind. Die Tabellen werden mit Daten aus den Dateien .csv im Verzeichnis /data/biketrips aufgefüllt.
Die Stationsdatendatei wird von der Seite station information heruntergeladen (und dann bearbeitet). Die aktualisierte Datei wird dann in ein neues HDFS-Verzeichnis /data/stations hochgeladen.
Die Wetterdaten werden aus einem öffentlichen Bucket in Object Storage heruntergeladen. Als Nächstes wird die Headerzeile aus der Datei entfernt. Die aktualisierte Datei wird dann in ein neues HDFS-Verzeichnis /data/weather hochgeladen. Als Nächstes werden eine neue weather-Hive-Datenbank und die Tabelle weather.weather_ext erstellt und mit Daten aus der Datei weather-newark-airport.csv im Verzeichnis /data/weather aufgefüllt.
Navigieren Sie zur Seite Citibike System Data, um alle verfügbaren Datendateien anzuzeigen. Klicken Sie im Abschnitt Citi Bike Trip Histories auf downloadable files of Citi Bike trip data. Auf der Seite Index of bucket "tripdata" werden die verfügbaren Datendateien angezeigt. In dieser Übung verwenden Sie nur einige der Datendateien auf dieser Seite.
In dieser Aufgabe laden Sie zwei Skripte herunter. Die Skripte und eine randomisierte Wetterdatendatei werden in einem öffentlichen Bucket in Object Storage gespeichert.
-
Um die Datendateien in einem Objekt wie dem biketrip-Objekt anzuzeigen, klicken Sie auf Einblenden
 neben dem Objektnamen. Die in diesem Objekt enthaltenen Dateien werden angezeigt. Um die Liste der Dateien auszublenden, klicken Sie neben dem Objektname auf Ausblenden
neben dem Objektnamen. Die in diesem Objekt enthaltenen Dateien werden angezeigt. Um die Liste der Dateien auszublenden, klicken Sie neben dem Objektname auf Ausblenden  .
.
Übung 8. Cluster verwalten
Zur Wartung Ihrer Cluster verwenden Sie die Seiten Cluster und Clusterdetails.
Mit Oracle Cloud Infrastructure Tagging können Sie Ressourcen Metadaten hinzufügen. Auf diese Weise lassen sich Schlüssel und Werte definieren und mit Ressourcen verknüpfen. Mithilfe der Tags können Sie Ressourcen basierend auf Ihren Geschäftsanforderungen organisieren und auflisten.
Sie können die Metriken des Clusters und aller zugehörigen Knoten überwachen.
-
Klicken Sie auf der Seite Cluster in die Spalte Name auf
training-cluster, um die Seite Clusterdetails anzuzeigen. - Scrollen Sie auf der Seite Clusterdetails nach oben. Klicken Sie im Abschnitt Ressourcen auf der linken Seite auf Clustermetriken.
- Im Abschnitt Clustermetriken werden die verschiedenen Metriken angezeigt, wie belegter HDFS-Speicherplatz, freier HDFS-Speicherplatz, abgeschlossene Yarn-Jobs und abgeschlossene Spark-Jobs. Sie können die Felder "Startzeit", "Endzeit", "Intervall", "Statistik" und "Optionen" nach Bedarf anpassen.
- Klicken Sie links im Abschnitt Ressourcen auf Knoten (7).
-
Klicken Sie auf einen beliebigen Knotennamenslink im Abschnitt Liste der Clusterknoten, um die zugehörigen Metriken anzuzeigen. Der Masterknoten
traininmn0in der Spalte Name. - Führen Sie auf der Seite Knotendetails einen Bildlauf zum Abschnitt Knotenmetriken durch. Dieser Abschnitt wird nur nach erfolgreicher Bereitstellung des Clusters unten auf der Seite Knotendetails angezeigt. Die folgenden Diagramme werden angezeigt: CPU-Auslastung, Speicherauslastung, Netzwerkbyte eingehend, Netzwerkbyte ausgehend und Datenträgerauslastung. Sie können mit der Maus auf ein beliebiges Diagramm zeigen, um weitere Details zu erhalten.
- über den Link Clusterdetails in den Navigationspfaden am oberen Seitenrand können Sie die Seite Clusterdetails erneut anzeigen.
Übung 9. Tutorialressourcen bereinigen
Sie können die Ressourcen löschen, die Sie in diesem Workshop erstellt haben. Wenn Sie die Übungen in diesem Workshop erneut bearbeiten möchten, führen Sie diese Löschaufgaben aus.
Wenn Sie die Ressourcen in der Datei training-compartment auflisten möchten, können Sie die Seite Mandanten-Explorer verwenden. Navigieren Sie im Menü Navigation zu Governance und Administration. Klicken Sie im Abschnitt Governance auf Mandanten-Explorer. Geben sie auf der Seite Mandanten-Explorer im Feld Compartments suchen training ein, und wählen Sie dann in der Liste der Compartments training-compartment aus. Die Ressourcen in training-compartment werden angezeigt.
- Öffnen Sie das Navigationsmenü, und wählen Sie Identität und Sicherheit aus. Wählen Sie unter Identität die Option Compartments aus.
- Suchen Sie in der Liste der verfügbaren Compartments nach Ihrem training-compartment.
- Klicken Sie in der Seite Compartments auf die Schaltfläche Aktionen, die mit training-compartment verknüpft ist. Wählen Sie Löschen aus dem Kontextmenü.
- Eine Bestätigungsmeldung wird angezeigt. Löschen. Der Status des gelöschten Compartments wechselt von Aktiv zu Wird entfernt, bis das Compartment erfolgreich gelöscht wird. Sie können in der Spalte Name auf den Link für die Compartment-Namen klicken, um den Status dieses Vorgangs anzuzeigen.
- Öffnen Sie das Navigationsmenü, und wählen Sie Identität und Sicherheit aus. Wählen Sie unter Identität die Option Policys aus.
- die Schaltfläche Aktionen, die mit der Policy training-admin-policy verknüpft ist, und wählen Sie im Kontextmenü die Option Löschen aus. Ein Bestätigungsmeldungsfeld wird angezeigt. Klicken Sie auf Löschen.
- die Schaltfläche Aktionen, die mit der Policy training-bds-policy verknüpft ist, und wählen Sie im Kontextmenü die Option Löschen aus. Ein Bestätigungsmeldungsfeld wird angezeigt. Klicken Sie auf Löschen.
- Navigieren Sie im Menü Navigation zu Networking. Klicken Sie im Abschnitt IP-Verwaltung auf Reservierte IPs. Die Seite Reservierte öffentliche IP-Adressen wird angezeigt.
- Stellen Sie sicher, dass im Listengeltungsbereich im linken Fensterbereich das training-compartment ausgewählt ist.
-
In diesem Workshop haben Sie drei reservierte IP-Adressen erstellt:
traininmn0-public-ip,traininqs0-public-ipundtraininun0-public-ip. -
die Schaltfläche Aktionen, die mit
traininmn0-public-ipverknüpft ist. Wählen Sie im Kontextmenü die Option Beenden. Eine Bestätigungsmeldung wird angezeigt. Beenden. -
die Schaltfläche Aktionen, die mit
traininqs0-public-ipverknüpft ist. Wählen Sie im Kontextmenü die Option Beenden. Eine Bestätigungsmeldung wird angezeigt. Beenden. -
die Schaltfläche Aktionen, die mit
traininun0-public-ipverknüpft ist. Wählen Sie im Kontextmenü die Option Beenden. Eine Bestätigungsmeldung wird angezeigt. Beenden.
Damit Sie einen Bucket löschen können, der Objekte enthält, müssen Sie zuerst alle Objekte im Bucket löschen.
- Sie können im Menü Navigation zu Speicher navigieren. Klicken Sie im Abschnitt Object Storage & Archive Storage auf Buckets. Die Seite Buckets wird angezeigt. Stellen Sie sicher, dass im Listengeltungsbereich im linken Fensterbereich das training-compartment ausgewählt ist. In der Liste der verfügbaren Buckets wird der neu erstellte Training-Bucket in der Spalte Name angezeigt. Der Link Training.
- Die Seite Bucket-Details für den Bucket training wird angezeigt. Scrollen Sie nach unten zum Abschnitt Objekte.
- Klicken Sie in der Zeile für das Objekt biketrips auf die Schaltfläche Aktionen, und wählen Sie im Kontextmenü die OptionOrdner löschen aus.
- Eine Bestätigungsmeldung wird angezeigt. Geben Sie biketrips in das Textfeld Geben sie den Namen des Ordners, um den Löschvorgang zu bestätigen ein. Klicken Sie dann auf Löschen. Das Objekt wird gelöscht, und die Seite Bucket-Details wird erneut angezeigt.
- Klicken Sie in der Zeile für das Objekt stations auf die Schaltfläche Aktionen, und wählen Sie im Kontextmenü die OptionOrdner löschen aus.
- Eine Bestätigungsmeldung wird angezeigt. Geben Sie stations in das Textfeld Name des Ordners eingeben, um den Löschvorgang zu bestätigen ein, und klicken Sie dann auf Löschen. Das Objekt wird gelöscht, und die Seite Bucket-Details wird erneut angezeigt.
- Klicken Sie in der Zeile für das Objekt weather auf die Schaltfläche Aktionen, und wählen Sie im Kontextmenü die OptionOrdner löschen aus.
- Eine Bestätigungsmeldung wird angezeigt. Geben Sie weather in das Textfeld Type the folder name to bestät ein, und klicken Sie dann auf Delete. Das Objekt wird gelöscht, und die Seite Bucket-Details wird erneut angezeigt.
- Scrollen Sie nach oben auf der Seite, und klicken Sie auf die Schaltfläche Löschen. Eine Bestätigungsmeldung wird angezeigt. Löschen. Der Bucket wird gelöscht, und die Seite Buckets wird erneut angezeigt.
Ein VCN kann nur gelöscht werden, wenn es leer ist und auch keine zugehörigen Ressourcen oder angehängten Gateways wie Internetgateway oder dynamisches Routinggateway hat. Auch die Subnetze eines VCN können nur gelöscht werden, wenn sie leer sind.
- Öffnen des Navigationsmenüs, und wählen Sie Networking aus. Wählen Sie dann Virtuelle Cloud-Netzwerke aus.
- Klicken Sie auf der Liste der verfügbaren VCNs in Ihrem Compartment in der Spalte Name auf den Namenslink training-vcn. Die Seite Details virtuelles Cloud-Netzwerk wird angezeigt.
- Klicken Sie im Abschnitt Subnetze auf die Schaltfläche Aktionen, die mit Private Subnetz-training-vcn verknüpft ist. Wählen Sie im Kontextmenü die Option Beenden. Eine Bestätigungsmeldung wird angezeigt. Beenden.
- Klicken Sie im Abschnitt Subnetze auf die Schaltfläche Aktionen, die mit Öffentliches Subnetz-training-vcn verknüpft ist. Wählen Sie im Kontextmenü die Option Beenden. Eine Bestätigungsmeldung wird angezeigt. Beenden.
- Klicken Sie im Abschnitt Ressourcen im linken Fensterbereich auf Routentabellen.
- Klicken Sie im Abschnitt Routentabellen auf die Schaltfläche Aktionen, die mit Routentabelle für privates Subnetz-training-vcn verknüpft ist. Wählen Sie im Kontextmenü die Option Beenden. Eine Bestätigungsmeldung wird angezeigt. Beenden.
- Klicken Sie im Abschnitt Routentabellen in der Spalte Name auf den Link Standardroutentabelle für training-vcn. Die Seite Routentabellendetails wird angezeigt. Klicken Sie im Abschnitt Routingregeln auf das Symbol Aktionen, das mit Internetgateway-training-vcn verknüpft ist. Wählen Sie im Kontextmenü die Option Entfernen. Eine Bestätigungsmeldung wird angezeigt. Entfernen: training-vcn in den Navigationspfaden, um zur Seite training-vcn zurückzukehren.
- Klicken Sie im Abschnitt Ressourcen im linken Fensterbereich auf Internetgateways. Klicken Sie im Abschnitt Internetgateways auf die Schaltfläche Aktionen, die mit Internetgateway-training-vcn verknüpft ist. Wählen Sie im Kontextmenü die Option Beenden. Eine Bestätigungsmeldung wird angezeigt. Beenden.
- Klicken Sie im Abschnitt Ressourcen im linken Fensterbereich auf Sicherheitslisten. Klicken Sie im Abschnitt Sicherheitslisten auf die Schaltfläche Aktionen, die mit Sicherheitsliste für private Subnetz-training-vcn verknüpft ist. Wählen Sie im Kontextmenü die Option Beenden. Eine Bestätigungsmeldung wird angezeigt. Beenden.
- Klicken Sie im Abschnitt Ressourcen im linken Fensterbereich auf NAT-Gateways. Klicken Sie im Abschnitt NAT-Gateways auf die Schaltfläche Aktionen, die mit NAT-Gateway-training-vcn verknüpft ist. Wählen Sie im Kontextmenü die Option Beenden. Eine Bestätigungsmeldung wird angezeigt. Beenden.
- Klicken Sie im linken Fensterbereich im Abschnitt Ressourcen auf Servicegateways. Klicken Sie im Abschnitt Servicegateways auf die Schaltfläche Aktionen, die mit Servicegateway-training-vcn verknüpft ist. Wählen Sie im Kontextmenü die Option Beenden. Eine Bestätigungsmeldung wird angezeigt. Beenden.
- Klicken Sie am oberen Rand der Seite auf Beenden, um das VCN zu beenden. Das Fenster Virtuelles Cloud-Netzwerk beenden wird angezeigt. Nach weniger als einer Minute ist die Schaltfläche Alle beenden aktiviert. Um Ihr VCN zu löschen, klicken Sie auf Alle beenden.
- Wenn der Beendigungsvorgang erfolgreich abgeschlossen ist, wird im Fenster eine Meldung Beenden des virtuellen Cloud-Netzwerks ist abgeschlossen angezeigt. Schließen.
Was kommt als Nächstes
Erfahren Sie mehr über Big Data Service, oder probieren Sie andere Workshops aus.