JupyterHub mit Notizbüchern verwenden
Mit JupyterHub können mehrere Benutzer zusammenarbeiten, indem für jeden Benutzer ein eigener Jupyter-Notebook-Server bereitgestellt wird. Wenn Sie ein Big Data Service-Cluster erstellen, wird JupyterHub installiert und auf den Cluster-Knoten konfiguriert.
Hinweis
JupyterHub ist nur in Big Data Service 3.0.7-Clustern und höher verfügbar.
Informationen zu Big Data Service 3.0.26 ODH 1.x-Clustern oder früheren Clustern finden Sie unter JupyterHub in Big Data Service 3.0.26 oder früher verwenden.
Informationen zu Big Data Service 3.0.27 ODH 2.x-Clustern oder höher finden Sie unter JupyterHub in Big Data Service 3.0.27 oder höher verwenden.
Kernels starten und Spark-Jobs ausführen
- Rufen Sie JupyterHub auf.
- Öffnen Sie einen Notizbuchserver. Sie werden zur Launcher-Seite umgeleitet.
- Sie können einen von mehreren standardmäßig verfügbaren Kernels öffnen, wie Python, PySpark, Spark und SparkR. Um ein Notizbuch zu starten, wählen Sie Datei > Neu > Notizbuch und dann Kernel auswählen aus, oder wählen Sie das entsprechende Symbol unter "Notizbuch" aus.
Beispielcode für Python-Kernel:
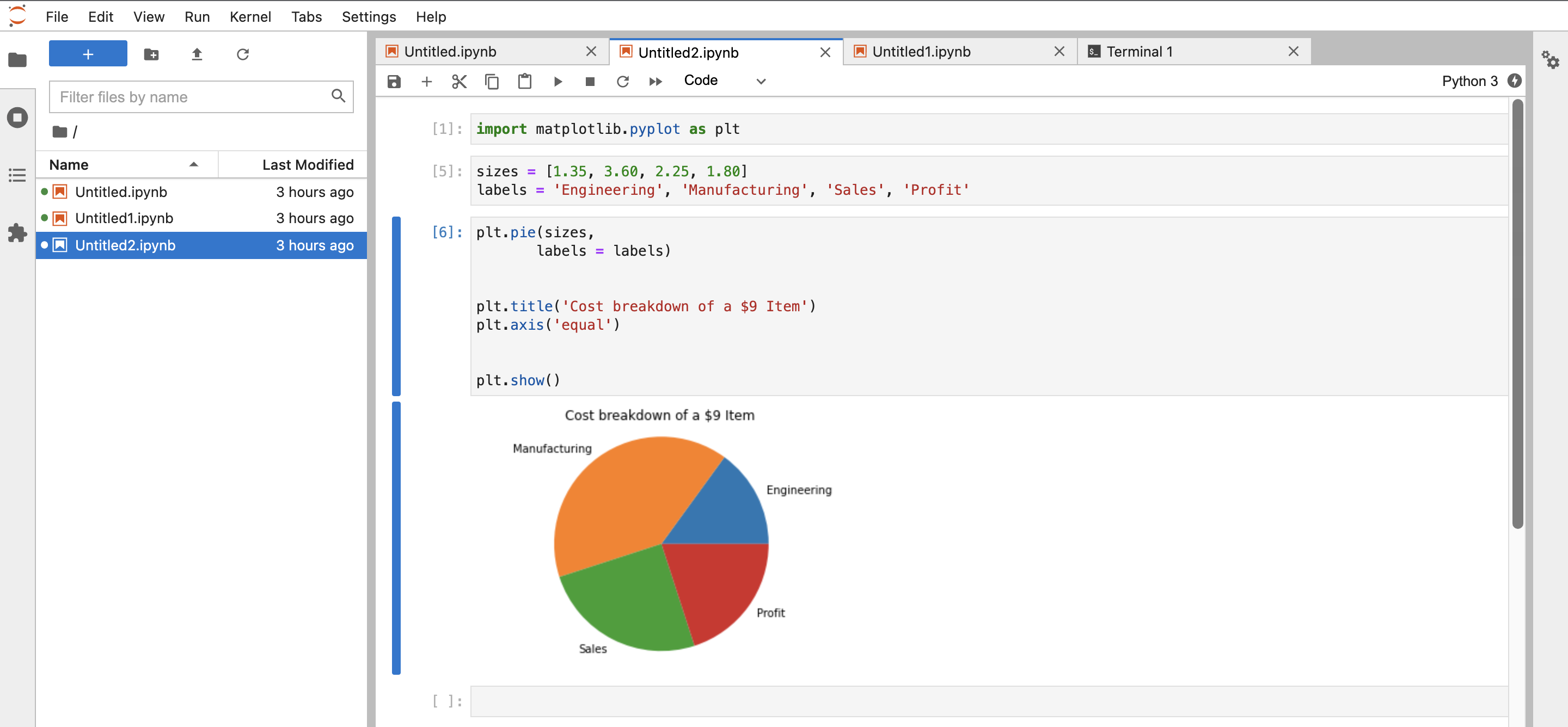
Beispielcode für SparkMagic in PySpark-Kernel