GPU verwenden
Data Flow unterstützt vollständig verwaltete GPU-basierte Spark, um die Daten- und KI-ML-Pipeline zu beschleunigen und zu vereinheitlichen.
Der Spark RAPIDS-Beschleuniger von NVIDIA beschleunigt ETL auf Data Flow transparent und optimiert das Preis-Leistungs-Verhältnis. Führen Sie vorhandene Data Flow Spark-Anwendungen auf GPU ohne Codeänderungen aus, um die Vorteile der NVIDIA RAPIDS-Beschleunigung zu nutzen.
Voraussetzung
Die Spark-Mindestversion zur Ausführung von GPU-Ausprägungen in Data Flow ist Spark 3.2.1. Wenn Sie GPU-Ausprägungen in Data Flow verwenden möchten, reichen Sie eine Serviceanfrage für Oracle Cloud Infrastructure Data Flow ein. Geben Sie die gewünschte GPU-Ausprägung und den Anwendungsfall an. Diese Informationen werden verwendet, um das erforderliche Limit und die erforderliche Quota-Erhöhung für Ihren Mandanten durchzuführen.
Unterstützte Formen
- VM.GPU.A10: X9-basierte GPU-Compute-Auslastung.
-
- GPU: NVIDIA A10 24 GB
- CPU: Intel Xeon Platinum 8358. Basisfrequenz 2,6 GHz, max. Turbofrequenz 3,4 GHz.
| Form | Anzahl OCPUs | GPU-Arbeitsspeicher (GB) | CPU-Arbeitsspeicher (GB) | Block Storage (GB) | Maximale Netzwerkbandbreite (Gbit/s) | Maximale Gesamtzahl von VNICs (Linux) |
|---|---|---|---|---|---|---|
| VM.GPU.A10.1 (GPU: 1xA10 | 15 | 24 | 240 | 1.575 | 24 | 15 |
| VM.GPU.A10.2 (GPU: 2xA10) | 30 | 48 | 480 | 3.075 | 48 | 24 |
Weitere Informationen finden Sie in der Compute-Dokumentation.
Erste Schritte mit GPU-Ausprägungen für Spark in Data Flow
Wenn Sie CPU- und GPU-Ausprägungen verschiedener Architekturen für Treiber und Executors mischen und abgleichen, stellen Sie sicher, dass die Anwendung und alle Abhängigkeiten architekturunabhängig sind.
- Optionen --jars und --conf verwenden
- Dieser Spark-Submit-kompatible Befehl verwendet den enthaltenen NVIDIA RAPIDS-Beschleuniger für Apache Spark:
oci --profile <cli-profile> --auth security_token data-flow run submit \ --compartment-id <compartment-id> \ --execute "--jars oci://dataflow_sample_apps@bigdatadatasciencelarge/rapids-4-spark_2.12-23.06.0.jar \ --driver-shape "VM.GPU.A10.1" \ --executor-shape "VM.GPU.A10.1" \ --num-executors 1 --spark-version "3.2.1" \ --conf spark.rapids.sql.explain=ALL \ --conf spark.plugins=com.nvidia.spark.SQLPlugin \ --class com.oracle.oci.dataflow.samples.DataFlowJavaSample \ oci://dataflow_sample_apps@bigdatadatasciencelarge/dataflow-java-sample-1.0-SNAPSHOT.jar" - Optionen --packages und --conf verwenden
- Dieser spark-submit-kompatible Befehl ruft den neuesten NVIDIA RAPIDS-Beschleuniger für Apache Spark aus dem Maven-Repository ab:
oci --profile <cli-profile> --auth security_token data-flow run submit \ --compartment-id <compartment-id> \ --driver-shape "VM.GPU.A10.1" \ --executor-shape "VM.GPU.A10.1" \ --num-executors 1 \ --spark-version "3.2.1" \ --execute "--packages com.nvidia:rapids-4-spark_2.12-23.06.0 \ --conf spark.rapids.sql.explain=ALL --conf spark.plugins=com.nvidia.spark.SQLPlugin \ --class com.oracle.oci.dataflow.samples.DataFlowJavaSample oci://dataflow_sample_apps@bigdatadatasciencelarge/dataflow-java-sample-1.0-SNAPSHOT.jar"
Die neueste Spark-RAPIDS-Version finden Sie unter NVIDIA Spark RAPIDS-Downloadversion. Weitere Optimierungsoptionen finden Sie unter RAPIDS-Plug-in für Apache Spark Developer - Überblick.
Der Spark RAPIDS-Beschleuniger von NVIDIA kann transparent ETL beschleunigen und das Preis-Leistungs-Verhältnis in OCI Data Flow optimieren. Sie können vorhandene Data Flow Spark-Anwendungen auf GPUs ohne Codeänderungen ausführen, um die Vorteile der NVIDIA RAPIDS-Beschleunigung zu nutzen.
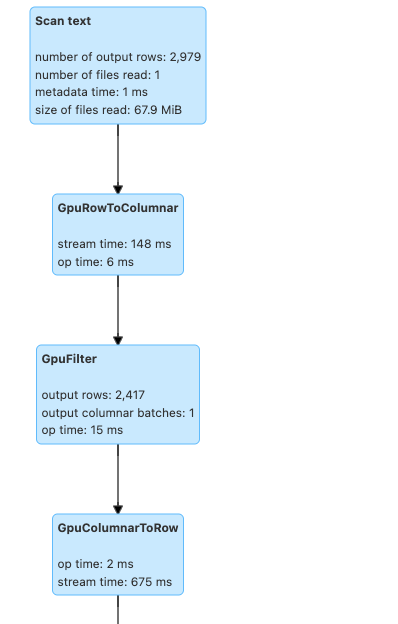
Wenn Sie den Spark RAPIDS-Beschleuniger von NVIDIA für die GPU verwenden, die in Data Flow ausgeführt wird, zeigt die Spark-UI alle CPU-Vorgänge an, die durch GPU-Vorgänge mit einem "GPU"-Präfix ersetzt werden. Beispiele: