Table Extraction
Table extraction can be used to identify tables in a document and extract their contents. For example, if a PDF receipt contains a table that includes the taxes and total amount, Document Understanding identifies the table and extracts the table structure.
Document Understanding provides the number of rows and columns for the table and the contents in each table cell. Each cell has a confidence score. The confidence score is a decimal number. Scores closer to 1 indicate a higher confidence in the extracted text, while lower scores indicate lower confidence score. The range of the confidence score for each label is from 0 to 1.
Supported features are:
- Table extraction for tables with and without borders
- Bounding polygons
- Confidence score
- Single request
- Batch request
- English language only
Table Extraction Example
An example of table extraction use in Document Understanding.
- Input document
-
Table Extraction Input
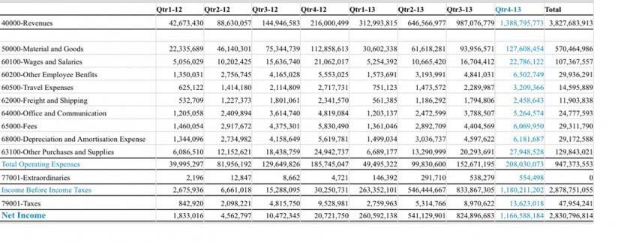 API Request:
API Request:{ "processorConfig": { "processorType": "GENERAL", "features": [ { "featureType": "TABLE_EXTRACTION" } ] }, "inputLocation": { "sourceType": "OBJECT_STORAGE_LOCATIONS", "objectLocations": [ { "source": "OBJECT_STORAGE", "namespaceName": "", "bucketName": "", "objectName": "" } ] }, "compartmentId": "", "outputLocation": { "namespaceName": "", "bucketName": "", "prefix": "" } } - Output:
-
Table Extraction Output
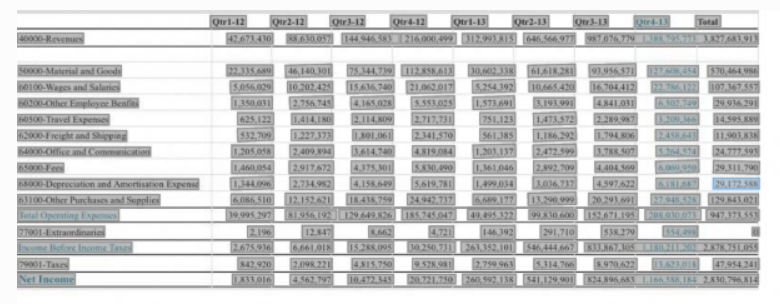 API Response:
API Response:{ "documentMetadata": { "pageCount": 1, "mimeType": "application/pdf" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 2575, "height": 1013, "unit": "PIXEL" }, ... "tables": [ { "rowCount": 15, "columnCount": 9, "bodyRows": [ { "cells": [ { "text": "Qtr1-12", "rowIndex": 0, "columnIndex": 1, "confidence": 0.92011595, "boundingPolygon": { "normalizedVertices": [ { "x": 0.2532038834951456, "y": 0.022704837117472853 }, { "x": 0.3005825242718447, "y": 0.022704837117472853 }, { "x": 0.3005825242718447, "y": 0.05330700888450148 }, { "x": 0.2532038834951456, "y": 0.05330700888450148 } ] }, "wordIndexes": [ 0 ] }, { "text": "Qtr2-12", "rowIndex": 0, "columnIndex": 2, "confidence": 0.919653, "boundingPolygon": { "normalizedVertices": [ { "x": 0.33048543689320387, "y": 0.022704837117472853 }, { "x": 0.3724271844660194, "y": 0.022704837117472853 }, { "x": 0.3724271844660194, "y": 0.05330700888450148 }, { "x": 0.33048543689320387, "y": 0.05330700888450148 } ] }, "wordIndexes": [ 1 ] }, ...