Pipelines
A Data Science machine learning (ML) pipeline is a resource that defines a workflow of tasks, called steps.
ML is often a complex process, involving several steps working together in a workflow, to create and serve a machine learning model. Those steps usually include: data acquisition and extraction, data preparation for ML, featurization, training a model (including algorithm selection and hyper-parameter tuning), model evaluation, and model deployment.
Pipeline steps can have dependencies on other steps to create the workflow. Each step is discrete so gives you the flexibility to mix different environments and even different coding languages in the same pipeline.
A typical pipeline (workflow) includes these steps:
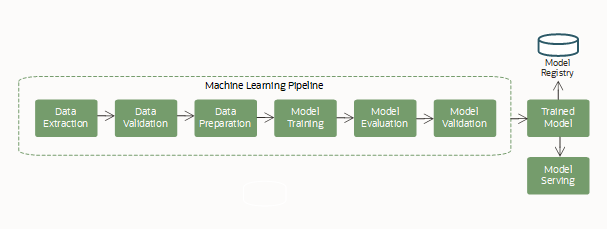
This ML life cycle run as a repeatable and continuous ML pipeline.
Pipeline Concepts
A pipeline could look like the following workflow:
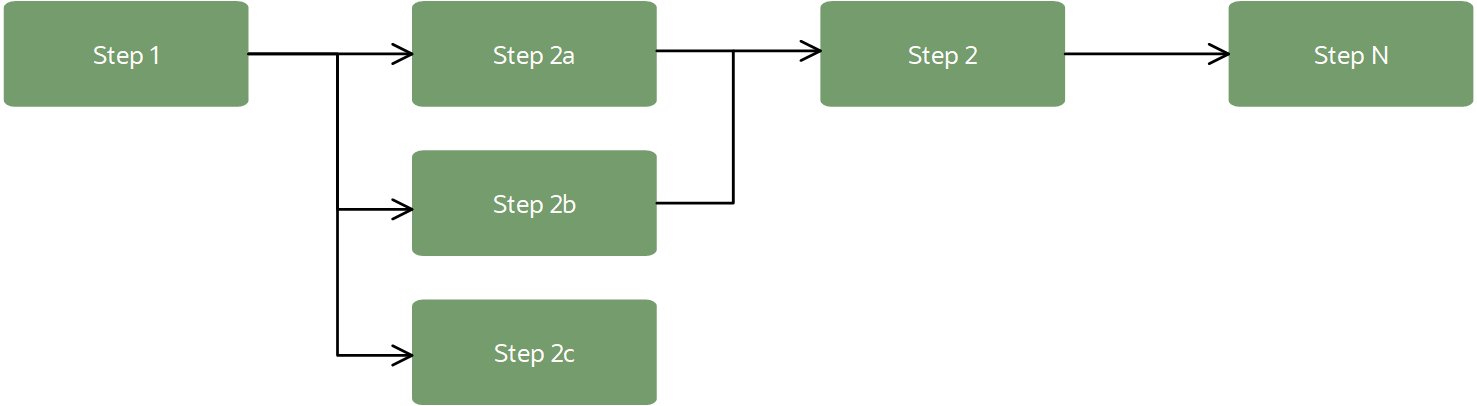
In an ML context, pipelines usually provide a workflow for data import, data transformation, model training, and model evaluation. Steps in the pipeline can be run in sequence or in parallel, as long as they're creating a directed acyclic graph (DAG).
- Pipeline
-
A resource that holds all the steps and their dependencies (the DAG workflow). You can define default configurations for infrastructure, logs, and other settings to use in pipeline resources. These default settings are used when not defined in the pipeline steps.
You can also edit some of the pipeline's configuration after it's created, such as the name, log, and custom environment variables.
- Pipeline Step
-
A task to be run in a pipeline. The step contains the step artifact, the infrastructure (compute shape, block volume) to use when running, log settings, environment variables, and others.
A pipeline step can be one of these types:
- A script (code files. Python, Bash, and Java are supported), and a configuration to run it.
-
An existing job in Data Science identified by its OCID.
- Step Artifact
-
Required when working with a script step type. An artifact is all the code to use to run the step. The artifact itself must be a single file. However, it can be a compressed (zip) file that includes several files. You can define the specific file to run when running the step.
All script steps in a pipeline must have an artifact for the pipeline to be in ACTIVE state so that it can be run.
- DAG
-
The steps workflow, defined by dependencies of each step on other steps in the pipeline. the dependencies create a logical workflow, or graph (must be acyclic). The pipeline strives to run steps in parallel to optimize the pipeline completion time unless the dependencies force steps to run sequentially. For example, training must be completed before evaluating the model, but several models can be trained in parallel to compete for best model.
- Pipeline Run
-
The execution instance of a pipeline. Each pipeline run includes its step runs. A pipeline run can be configured to override some of the pipeline's defaults before starting the execution.
- Pipeline Step Run
-
The run instance of a pipeline step. The configuration for the step run is taken from the pipeline run first when defined, or from the pipeline definition secondarily.
- Pipeline Lifecycle State
-
As the pipeline is being created, constructed, and even deleted it can be in various states. After the pipeline creation, the pipeline is in the CREATING state and can't be run until all steps have an artifact or job to run, then the pipeline changes to ACTIVE state.
- Access to OCI Resources
-
Pipeline steps can access all OCI resources in a tenancy, as long as there is a policy to allow it. You can run pipelines against data in ADW or Object Storage. Also, you can use vaults to provide secure way to authenticate against third-party resources. Pipeline steps can access external sources if you have configured the appropriate VCN.