Uso de blocs de notas para conectarse a Data Flow
Puede conectarse a Data Flow y ejecutar una aplicación Apache Spark desde una sesión de bloc de notas de Data Science. Estas sesiones le permiten ejecutar cargas de trabajo interactivas de Spark en un cluster de Data Flow de larga duración mediante una integración de Apache Livy.
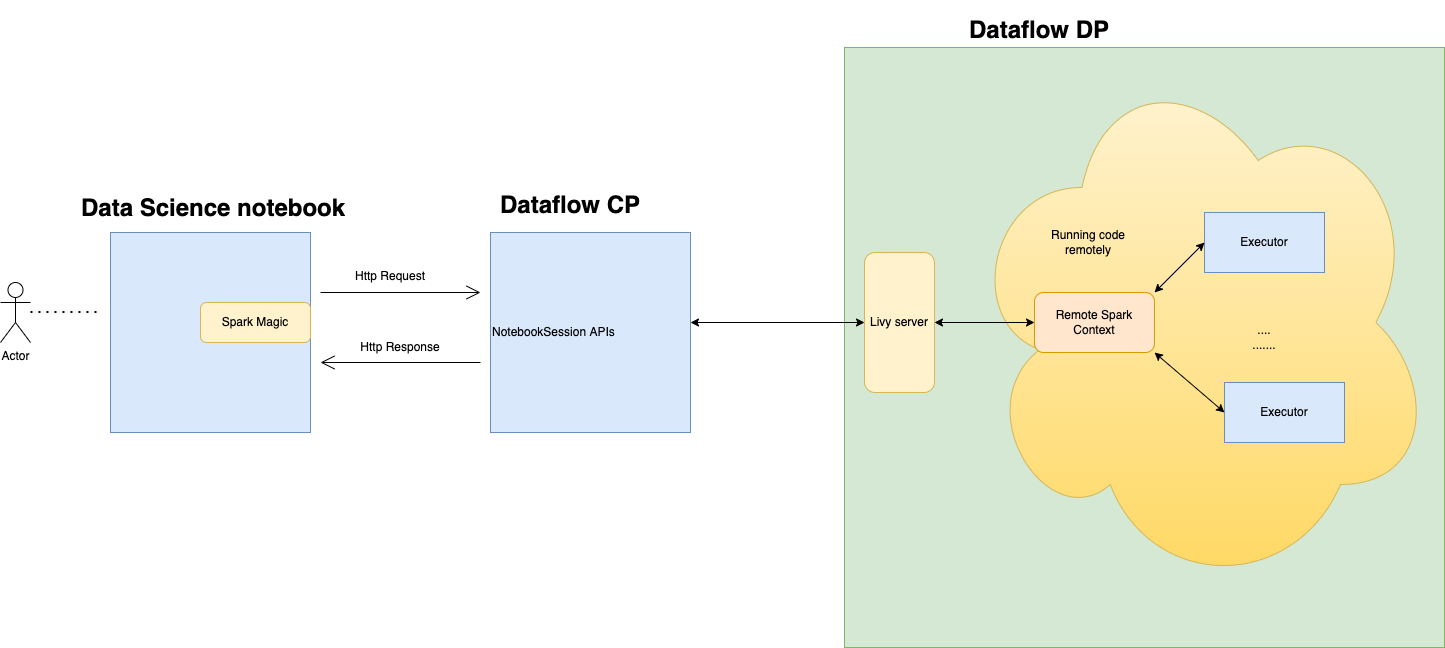
Data Flow utiliza blocs de notas de Jupyter totalmente gestionados para permitir a los científicos de datos e ingenieros de datos crear, visualizar, colaborar y depurar aplicaciones de ingeniería de datos y ciencia de datos. Puede escribir estas aplicaciones en Python, Scala y PySpark. También puede conectar una sesión de Notebook de Data Science a Data Flow para ejecutar aplicaciones. Los núcleos y las aplicaciones de Data Flow se ejecutan en Oracle Cloud Infrastructure Data Flow. Data Flow es un servicio de Apache Spark totalmente gestionado que realiza tareas de procesamiento de juegos de datos de gran tamaño sin necesidad de desplegar ni gestionar la infraestructura. Para obtener más información, consulte la documentación de Data Flow.
Apache Spark es un sistema informático distribuido diseñado para procesar datos a escala. Soporta SQL a gran escala, el procesamiento por lotes y de flujos, y tareas de Machine Learning. Spark SQL proporciona soporte similar a una base de datos. Para consultar datos estructurados, utilice Spark SQL. Se trata de una implantación de SQL estándar ANSI.
Data Flow es un servicio de Apache Spark totalmente gestionado que realiza tareas de procesamiento de juegos de datos de gran tamaño sin infraestructura que desplegar ni gestionar. Puede utilizar Spark Streaming para realizar ETL en la nube en sus datos de transmisión producidos continuamente. Permite una entrega rápida de aplicaciones porque puede centrarse en el desarrollo de aplicaciones, no en la gestión de la infraestructura.
Apache Livy es una interfaz de REST para Spark. Envíe trabajos de Spark tolerantes a fallos desde el bloc de notas mediante métodos síncronos y asíncronos para recuperar la salida.
SparkMagic permite la comunicación interactiva con Spark mediante Livy. Utilizando la directiva mágica `%%spark` dentro de una celda de código de JupyterLab. Los comandos SparkMagic se pueden utilizar para Spark 3.2.1 y el entorno conda de Data Flow.
Las sesiones de Data Flow soportan las capacidades de cluster de escala automática de Data Flow. Para obtener más información, consulte Ampliación automática en la documentación de Data Flow. Las sesiones de Data Flow soportan el uso de entornos conda como entornos de tiempo de ejecución de Spark personalizables.
- Limitaciones
-
-
Las sesiones de Data Flow duran hasta 7 días o 10 080 minutos (maxDurationInMinutes).
- Las sesiones de Data Flow tienen un valor de timeout de inactividad por defecto de 480 minutos (8 horas) (idleTimeoutInMinutes). Puede configurar un valor diferente.
- La sesión de Data Flow solo está disponible a través de una sesión de Data Science Notebook.
- Solo está soportada la versión 3.2.1 de Spark.
-
Vea el vídeo de tutorial sobre el uso de Data Science con Data Flow. Consulte también la documentación del SDK de Oracle Accelerated Data Science para obtener más información sobre la integración de Data Science y Data Flow.