Trabajos
Los trabajos de Data Science permiten realizar tareas personalizadas que puede aplicar cualquier caso de uso que tenga, como la preparación de datos, el entrenamiento de modelos, el ajuste de hiperparámetros, la inferencia por lotes, etc.
Con los trabajos, puede:
-
Ejecute tareas de aprendizaje automático (ML) o ciencia de datos fuera de las sesiones de Notebook en JupyterLab.
-
Ejecutar tareas discretas de ciencia de datos y tareas de Machine Learning como operaciones ejecutables y reutilizables.
-
Automatice el pipeline típico MLOps o de integración y despliegue continuos.
-
Ejecutar cargas de trabajo o lotes activados por eventos o acciones.
-
Inferencia de trabajo por lotes, minilotes o lotes distribuidos.
-
Proceso de cargas de trabajo en batch.
-
Traiga su propio contenedor.
Normalmente, un proyecto de AA y ciencia de datos es una serie de pasos que incluyen:
-
Acceder
-
Explorar
-
Preparar
-
Crear modelo
-
Entrenar
-
Validar
-
Desplegar
-
Probar
Una vez completados los pasos, puede automatizar el proceso de exploración de datos, entrenamiento del modelo, despliegue y prueba mediante trabajos. Un solo cambio en la preparación de datos o el entrenamiento de modelos, los experimentos con ajustes de hiperparámetros podrían ejecutarse como trabajo y probarse de forma independiente.
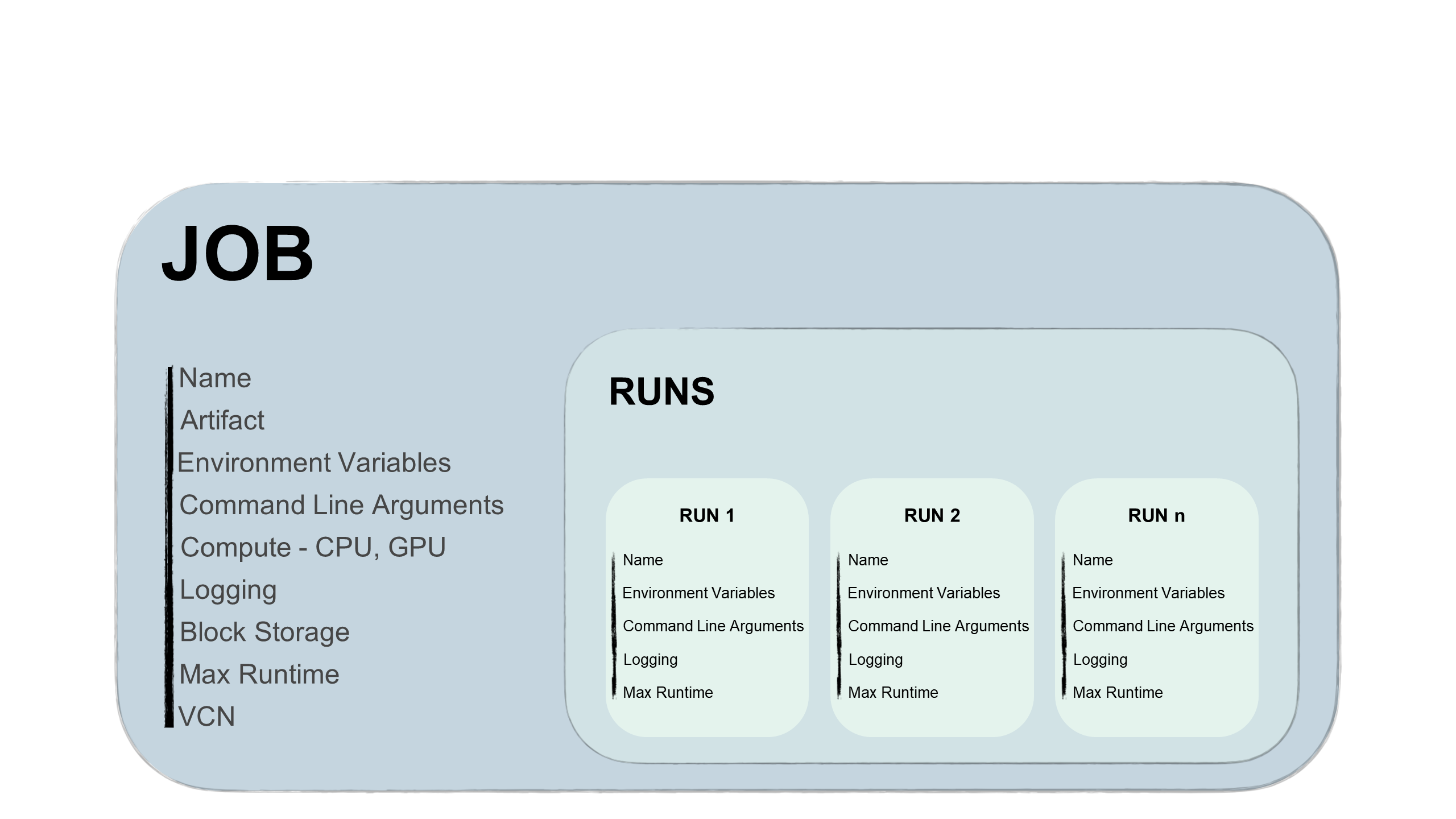
Los trabajos tienen dos partes, un trabajo y una ejecución de trabajo:
- Trabajo
-
Un trabajo es una plantilla que describe la tarea. Contiene elementos como el artefacto de trabajo que es inmutable y no se puede cambiar después de cargarlo en un trabajo. Además, el trabajo contiene información sobre las unidades de computación en las que se ejecuta el trabajo, las opciones de registro, el almacenamiento de bloques y otras opciones. Puede agregar variables de entorno o argumentos de la CLI para que los trabajos sean únicos o similares para todas las ejecuciones de trabajos futuras. Puede sustituir estas variables y argumentos en las ejecuciones de trabajos.
Puede editar la unidad de computación en el trabajo y entre ejecuciones de trabajos. Por ejemplo, si desea ejecutar una ejecución de trabajo en una unidad más potente, puede editar la unidad de computación del trabajo y, a continuación, iniciar una nueva ejecución de trabajo.
Consejo
No es necesario esperar a que termine la ejecución del trabajo para editar la unidad.
- Ejecución de trabajo
-
Una ejecución de trabajo es el procesador de trabajos real. En cada ejecución de trabajo, puede sustituir algunas opciones de configuración de trabajo y, sobre todo, las variables de entorno y los argumentos de la CLI. Puede tener el mismo trabajo con varias ejecuciones de trabajos iniciadas de forma secuencial o simultánea con diferentes parámetros. Por ejemplo, puede experimentar cómo funciona el mismo proceso de entrenamiento de modelo proporcionando diferentes hiperparámetros.
Ciclo de vida de los trabajos
Cada etapa del ciclo de vida del trabajo dispara eventos que se pueden utilizar para enviar notificaciones, disparar funciones de terceros o incluso otras ejecuciones de trabajos.
- Creación de trabajos
-
Creación de trabajos se genera al crear una configuración de trabajo, incluida la especificación de un archivo de artefacto de trabajos. El artefacto de trabajo contiene el código ejecutable del trabajo. Este artefacto puede ser Python, Bash/Shell o un archivo zip o tar comprimido que contiene un proyecto completo escrito en Python o Java.
Además, especifique la unidad de computación para ejecutar el artefacto de trabajo, así como el almacenamiento de bloques y la red. Puede seleccionar varias unidades de CPU y GPU, así como un almacenamiento de bloques de hasta 1 TB. La opción de registro permite definir la creación automática del registro para cada ejecución de trabajo.
Los montajes de almacenamiento se pueden usar de la siguiente manera:
- Almacenar logs durante el entrenamiento del modelo al que se puede acceder desde otro lugar.
- Almacene los puntos de control durante el entrenamiento del modelo para que pueda seguir entrenando un modelo desde el último punto de control y evitar iniciar el entrenamiento desde el principio.
- Almacenamiento y lectura de datos del montaje común del sistema de archivos para que no tenga que copiar los datos en la máquina que ejecuta el trabajo.
- Inicio de ejecuciones de trabajos
-
Se trata del procesador de trabajos. El inicio de una ejecución de trabajo permite cambiar algunos parámetros configurados para cambiar el caso de uso.
La ejecución del trabajo utiliza varias operaciones de ciclo de vida. Para una ejecución en el trabajo, el servicio Data Science gestiona la ejecución en el aprovisionamiento de la infraestructura, la ejecución en el artefacto del trabajo y el desaprovisionamiento de la infraestructura cuando se completa su ejecución.
Un trabajo puede tener muchas ejecuciones de trabajo que se pueden ejecutar de forma secuencial o simultánea. Puede configurar un tiempo de ejecución máximo para la ejecución del trabajo. Cuando una ejecución de trabajo permanece en curso más allá del tiempo de ejecución máximo configurado, el servicio Data Science cancela automáticamente la ejecución del trabajo. Se recomienda configurar un tiempo de ejecución máximo en todas las ejecuciones de trabajos para evitar ejecuciones de trabajos sin control.
Nota
El límite superior para el tiempo de ejecución máximo es de 30 días para una ejecución de trabajo. Si este valor no está configurado, se aplica el límite de 30 días.
- Supervisión
-
Durante la ejecución del trabajo, puede supervisar el proceso activando registro con el servicio Logging. Los mensajes se registran para la ejecución del trabajo y el archivo de artefacto del trabajo.
La supervisión le ayuda a depurar posibles errores y a supervisar los recursos utilizados.
- Finalización
-
Una ejecución de trabajo finaliza con la salida del proceso de código. Dispara el ciclo de vida final de la ejecución de trabajo, que es la anulación del aprovisionamiento de la infraestructura. La infraestructura también se destruye cuando cancela una ejecución de trabajo.
Acceso de trabajos a recursos en la nube
Los trabajos pueden acceder a todos los recursos de OCI de un arrendamiento, siempre que haya una política que lo permita. Puede ejecutar trabajos en datos de ADW o de Object Storage. Además, puede utilizar almacenes para proporcionar una forma segura de autenticarse en recursos de terceros. Los trabajos pueden acceder a orígenes externos si ha configurado la VCN adecuada.
Acceso a ejecuciones de trabajos
Las ejecuciones de trabajos soportan el SDK y la API de OCI. Puede ejecutar trabajos desde todos los servicios de terceros externos posibles, por ejemplo:
- La máquina cliente, MLOps o el pipeline de integración y despliegue continuos.
- Pipelines de integración y despliegue continuos de Bitbucket o GitHub.
- Servicios de Oracle AI o de terceros.
- Servicio Events.
Puede crear trabajos e iniciar ejecuciones de trabajos en la consola de OCI, y también puede crear y ejecutar trabajos con:
-
Python
-
Java
-
JavaScript
-
TypeScript
-
Go
-
Ruby
-
CLI de OCI
-
Terraform