Otras formas de ejecutar trabajos
Puede utilizar trabajos de muchas maneras diferentes, como el uso de entornos conda y archivos zip.
Uso de archivos zip o tar comprimidos
Puede utilizar trabajos para ejecutar todo un proyecto de Python que archive en un único archivo.
Los archivos zip o tar comprimidos que se ejecutan como un trabajo pueden utilizar los Entornos conda del servicio de Data Science y los Entornos conda personalizados.
Para la ejecución del trabajo, debe apuntar al archivo de entrada principal mediante la variable de entorno JOB_RUN_ENTRYPOINT. Esta variable solo se utiliza con trabajos que utilizan artefactos de trabajo de tar comprimido o zip.
Uso de un entorno conda de Data Science
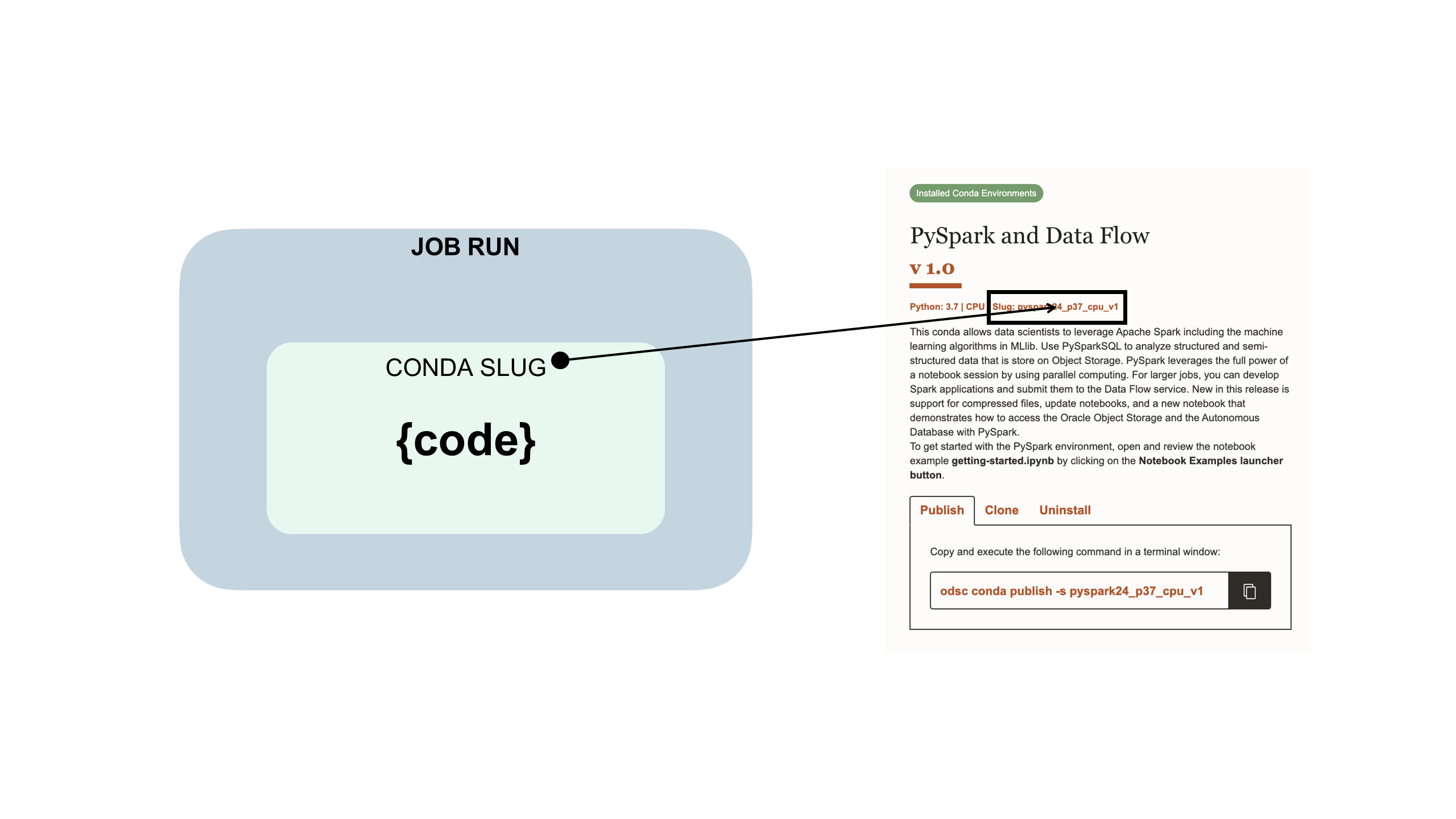
Puede utilizar uno de los entornos conda de Data Science que se incluyen en el servicio.
Un entorno conda encapsula todas las dependencias Python de terceros (como Numpy, Dask o XGBoost) que requiere la ejecución del trabajo. Los entornos conda de Data Science se incluyen y se conservan en el servicio. Si no especifica un entorno conda como parte de las configuraciones de trabajo y ejecución de trabajo, no se utilizará un entorno conda porque no hay ningún valor por defecto.
El código de trabajo está embebido en un entorno conda de Data Science:
Uso de un entorno conda personalizado
Puede utilizar trabajos de archivos zip y tar comprimido con entornos conda personalizados o con entornos conda de Data Science.
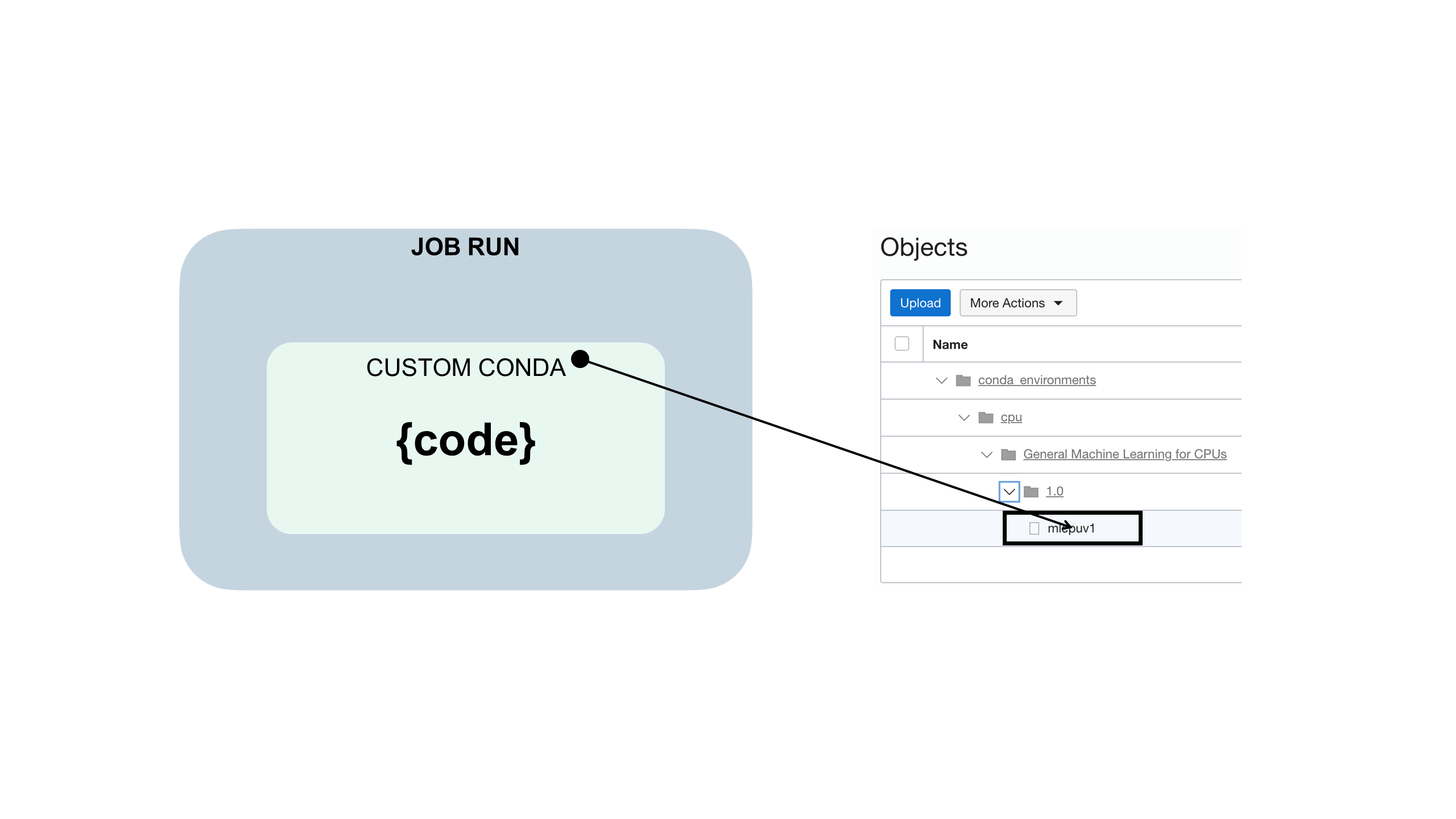
Un entorno conda encapsula todas las dependencias Python de terceros (como Numpy, Dask o XGBoost) que necesita su ejecución de trabajo. Puede crear, publicar y mantener entornos conda personalizados. Si no especifica un entorno conda como parte de las configuraciones de trabajo y ejecución de trabajo, no se utilizará un entorno conda porque no hay ningún valor por defecto
El código de trabajo se incrusta en un entorno conda personalizado como el siguiente:
Uso de un archivo YAML de tiempo de ejecución
Puede utilizar un archivo YAML de tiempo de ejecución para configurar variables de entorno de trabajo en lugar de utilizar la consola o el SDK.
Antes de empezar:
Descargue, descomprima y revise los archivos de ejemplo jobruntime.yaml y conda_pack_test.py para crear y probar el proyecto de trabajo.
El uso de un archivo jobruntime.yaml facilita la configuración de variables de entorno personalizadas en el proyecto.
Uso de Vault
Puede integrar el servicio OCI Vault en trabajos de Data Science mediante principales de recursos.
Antes de empezar:
-
Para que la entidad de recurso del trabajo tenga acceso a un almacén, asegúrese de que tiene un grupo dinámico en el compartimento que especifique la instancia o la entidad de recurso. Por ejemplo, puede utilizar la entidad de recurso y un grupo dinámico con esta regla:
all {resource.type='datasciencejobrun',resource.compartment.id='<compartment_ocid>'} -
Para que se ejecute el trabajo, debe asegurarse de que puede gestionar al menos secret-family en el grupo dinámico. Por ejemplo:
Allow dynamic-group <dynamic_group_name> to manage secret-family in compartment <compartment_name>La publicación de blog Using the OCI Instance Principals and Vault with Python to retrieve a Secret (Uso de Principales de instancia y Vault de OCI con Python para recuperar un secreto) proporciona detalles útiles.
-
Descargue, descomprima y revise el archivo de ejemplo
zipped_python_job.zipque muestra lo siguiente:- Inicialización del cliente de almacén en el trabajo mediante el SDK de Python.
- Lee un secreto mediante el OCID secreto.
- Decodifica el grupo de secretos y muestra el contenido del secreto real.
Puesto que los trabajos tienen acceso a la entidad de recurso, puede inicializar todos los clientes de Vault disponibles en el SDK de Python.
-
Cree un almacén que tenga una clave maestra y un secreto, y agregue una sentencia de política a todos los principales de recurso de trabajo en
manage secret-family.
- En la consola, cree un nuevo trabajo.
- Ejecute el trabajo para probar que funciona.
- Supervise la ejecución de trabajo para una finalización correcta.
- (Opcional) Si ha utilizado el registro, puede revisarlos para ver los valores de ejecución del trabajo.