Traiga su propio contenedor
Cree y utilice un contenedor personalizado (Bring Your Own Container o BYOC) como dependencia de tiempo de ejecución al crear un despliegue de modelo.
Con los contenedores personalizados, puede empaquetar dependencias de sistema e idioma, instalar y configurar servidores de inferencia y configurar diferentes tiempos de ejecución de idioma. Todo dentro de los límites definidos de una interfaz con un recurso de despliegue de modelo para ejecutar los contenedores.
BYOC permite la transferencia de contenedores entre diferentes entornos para que pueda migrar y desplegar aplicaciones en OCI Cloud.
Para ejecutar el trabajo, debe crear un Dockerfile y, a continuación, crear una imagen. Empiece por un Dockerfile que utilice una imagen de Python. Dockerfile se ha diseñado para que pueda crear compilaciones locales y remotas. Utilice la compilación local cuando realice una prueba local con el código. Durante el desarrollo local, no es necesario crear una nueva imagen para cada cambio de código.
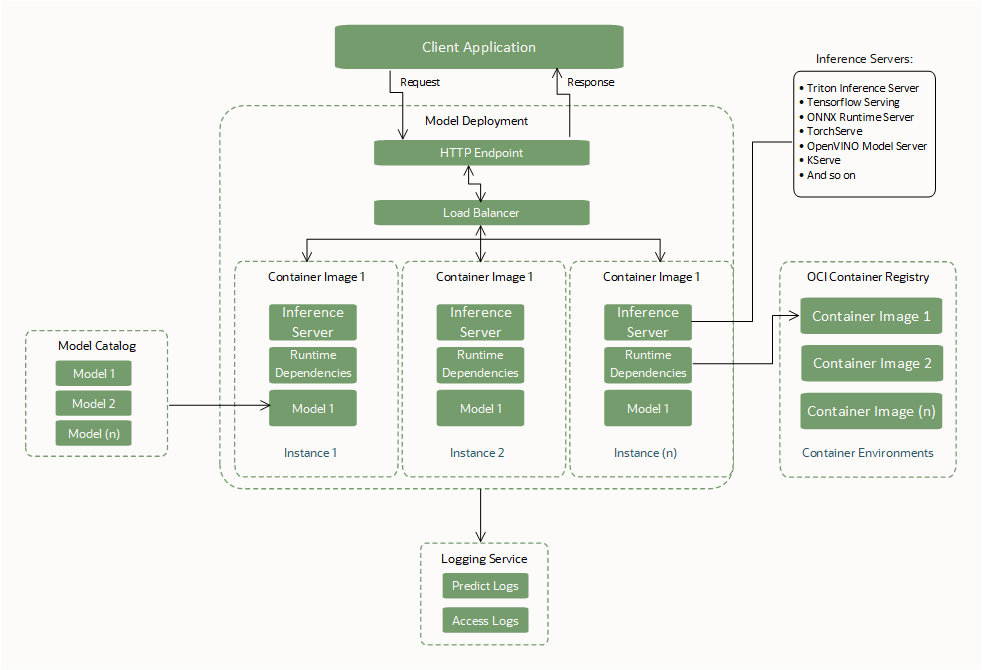
Interfaces requeridas de BYOC
Cree o especifique estas interfaces necesarias para utilizar un despliegue de modelo.
Artefacto del modelo
| Interfaz | Descripción |
|---|---|
| Cargue artefactos de modelo en el catálogo de modelos de Data Science. | Los artefactos de modelo, como la lógica de puntuación, el modelo de aprendizaje automático y los archivos dependientes, se deben cargar en el catálogo de modelos de Data Science antes de que los utilice un recurso de despliegue de modelo. |
| No hay archivos obligatorios. |
No hay archivos obligatorios para crear un despliegue de modelo BYOC. Nota: Cuando BYOC no se utiliza para un despliegue de modelo, los archivos |
| Ubicación de los artefactos de modelo montados. |
Durante los despliegues de modelos de inicialización, descomprima el artefacto de modelo y monte los archivos en el directorio Al comprimir un juego de archivos (incluido el modelo de aprendizaje automático y la lógica de puntuación) o una carpeta que contenga un juego de archivos, hay una ruta de ubicación diferente al modelo de aprendizaje automático dentro del contenedor. Asegúrese de que se utiliza la ruta correcta al cargar el modelo en la lógica de puntuación. |
Imagen de contenedor
| Interfaz | Descripción |
|---|---|
| Empaquetar dependencias de tiempo de ejecución. | Empaquete la imagen de contenedor con las dependencias de tiempo de ejecución necesarias para cargar y ejecutar el binario del modelo de aprendizaje automático. |
| Empaquetar un servidor web para exponer los puntos finales. |
Empaquete la imagen de contenedor con un servidor web sin estado basado en http (FastAPI, Flask, Triton, servidor TensorFlow, servidor PyTorch, etc.). Exponga un punto final
Nota: Si el punto final del servidor de inferencia no se puede personalizar para cumplir con la interfaz de punto final de Data Science, utilice un proxy (por ejemplo, NGINX) para asignar los puntos finales con comando de servicio a los puntos finales proporcionados por el marco. |
| Puertos expuestos. |
Los puertos que se utilizarán para los puntos finales Los puertos están limitados a entre 1024 y 65535. Se excluyen los puertos 24224, 8446 y 8447. El servicio expone los puertos proporcionados en el contenedor, por lo que no es necesario volver a exponerlos en el archivo Docker. |
| Tamaño de la imagen. | El tamaño de la imagen de contenedor está limitado a 16 GB en formato sin comprimir. |
| Acceso a la imagen. | El operador que crea el despliegue del modelo debe tener acceso a la imagen de contenedor para utilizarla. |
| Paquete Curl. | El paquete curl se debe instalar en la imagen de contenedor para que la política HEALTHCHECK de Docker se realice correctamente. Instale el último comando curl estable que no tenga vulnerabilidades abiertas. |
CMD, Entrypoint |
El archivo docker CMD o Entrypoint se debe proporcionar mediante la API o el archivo Docker que inician el servidor web. |
CMD, tamaño de Entrypoint. |
El tamaño combinado de CMD y Entrypoint no puede ser mayor que los 2048 bytes. Si el tamaño es superior a 2048 bytes, especifique los argumentos de la aplicación mediante el artefacto de modelo o utilice Object Storage para recuperar los datos. |
Recomendaciones generales
| Recomendación | Descripción |
|---|---|
| Empaquetar el modelo de aprendizaje automático en artefactos de modelo. |
Empaquetar el modelo de aprendizaje automático como artefacto y cargarlo en el catálogo de modelos de Data Science para utilizar las funciones de gobernanza de modelos y control de versiones de modelos, aunque existe una opción para empaquetar el modelo de aprendizaje automático en la imagen de contenedor. Guardado del modelo en el catálogo de modelos. Después de cargar el modelo en el catálogo de modelos y hacer referencia a él durante la creación del despliegue del modelo, Data Science descarga una copia del artefacto y lo descompone en el directorio |
| Proporcionar resumen de imagen e imagen para todas las operaciones | Recomendamos proporcionar el resumen de imagen y de imagen para crear, actualizar y activar operaciones de despliegue de modelo a fin de mantener la consistencia en el uso de la imagen. Durante una operación de actualización de una imagen diferente, tanto la imagen como el resumen de imagen son esenciales para actualizar a la imagen esperada. |
| Análisis de vulnerabilidades | Recomendamos utilizar el servicio OCI Vulnerability Scanning para explorar las vulnerabilidades de la imagen. |
| Campo de API nulo | Si un campo de API está vacío, no transfiera una cadena vacía, un objeto vacío ni una lista vacía. Transfiera el campo como nulo o no transfiera en absoluto a menos que desee transferir explícitamente como objeto vacío. |
Mejores prácticas de BYOC
- El despliegue de modelos solo soporta la imagen de contenedor que reside en OCI Registry.
- Asegúrese de que la imagen de contenedor existe en OCI Registry durante todo el ciclo de vida del despliegue del modelo. La imagen debe existir para garantizar la disponibilidad en caso de que una instancia se reinicie automáticamente o el equipo de servicio realice la aplicación de parches.
- BYOC solo soporta contenedores docker.
- Data Science utiliza el artefacto de modelo comprimido para traer la lógica de puntuación del modelo de aprendizaje automático y espera que esté disponible en el catálogo de modelos de Data Science.
- El tamaño de la imagen de contenedor está limitado a 16 GB en formato sin comprimir.
- Data Science agrega una tarea
HEALTHCHECKantes de iniciar el contenedor para que la políticaHEALTHCHECKno se tenga que agregar explícitamente en el archivo de Docker porque se ha sustituido. La comprobación del sistema comienza a ejecutarse 10 minutos después de que se inicie el contenedor y, a continuación, comprueba/healthcada 30 segundos, con un timeout de tres segundos y tres reintentos por comprobación. - Se debe instalar un paquete curl en la imagen de contenedor para que la política
HEALTHCHECKde Docker se realice correctamente. - El usuario que crea el recurso de despliegue de modelo debe tener acceso a la imagen de contenedor en OCI Registry para utilizarla. Si no es así, cree una política de IAM de acceso de usuario antes de crear un despliegue de modelo.
- El archivo docker
CMDoEntrypointse debe proporcionar mediante la API o Dockerfile, que inician el servidor web. - El tiempo de espera definido por el servicio para que se ejecute el contenedor es de 10 minutos, de modo que asegúrese de que el contenedor de servicio de inferencia se inicie (está en buen estado) dentro de este período de tiempo.
- Pruebe siempre el contenedor localmente antes de desplegarlo en la nube mediante un despliegue de modelo.
Resúmenes de imágenes de Docker
Las imágenes de un registro de Docker se identifican por repositorio, nombre y etiqueta. Además, Docker proporciona a cada versión de una imagen un resumen alfanumérico único. Al transferir una imagen de Docker actualizada, recomendamos proporcionar a la imagen actualizada una nueva etiqueta para identificarla, en lugar de reutilizar una etiqueta existente. Sin embargo, aunque introduzca una imagen actualizada y le asigne el mismo nombre y la etiqueta que una versión anterior, la nueva versión transferida tiene un resumen diferente de la versión anterior.
Al crear un recurso de despliegue de modelo, especifique el nombre y la etiqueta de una versión concreta de una imagen en la que basar el despliegue de modelo. Para evitar inconsistencias, el despliegue del modelo registra el resumen único de esa versión de la imagen. También puede proporcionar el resumen de la imagen al crear un despliegue de modelo.
Por defecto, al transferir una versión actualizada de una imagen al registro de Docker con el mismo nombre y etiqueta que la versión original de la imagen en la que se basa el despliegue de modelo, sigue utilizando el resumen original para extraer la versión original de la imagen. Si desea que el despliegue de modelo extraiga la versión posterior de la imagen, puede cambiar explícitamente el nombre de la imagen con una etiqueta y un resumen que utilice el despliegue de modelo para identificar qué versión de la imagen extraer.
Preparación del artefacto de modelo
Cree un archivo zip de artefacto y guárdelo con el modelo en el catálogo de modelos. El artefacto incluye el código para operar el contenedor y ejecutar las solicitudes de inferencia.
El contenedor debe exponer un punto final /health para devolver el estado del servidor de inferencia y un punto final /predict para inferir.
El siguiente archivo Python del artefacto de modelo define estos puntos finales mediante un servidor Flask con el puerto 5000:
# We now need the json library so we can load and export json data
import json
import os
import numpy as np
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neural_network import MLPClassifier
import pandas as pd
from joblib import load
from sklearn import preprocessing
import logging
from flask import Flask, request
# Set environnment variables
WORK_DIRECTORY = os.environ["WORK_DIRECTORY"]
TEST_DATA = os.path.join(WORK_DIRECTORY, "test.json")
MODEL_DIR = os.environ["MODEL_DIR"]
MODEL_FILE_LDA = os.environ["MODEL_FILE_LDA"]
MODEL_PATH_LDA = os.path.join(MODEL_DIR, MODEL_FILE_LDA)
# Loading LDA model
print("Loading model from: {}".format(MODEL_PATH_LDA))
inference_lda = load(MODEL_PATH_LDA)
# Creation of the Flask app
app = Flask(__name__)
# API 1
# Flask route so that we can serve HTTP traffic on that route
@app.route('/health')
# Get data from json and return the requested row defined by the variable Line
def health():
# We can then find the data for the requested row and send it back as json
return {"status": "success"}
# API 2
# Flask route so that we can serve HTTP traffic on that route
@app.route('/predict',methods=['POST'])
# Return prediction for both Neural Network and LDA inference model with the requested row as input
def prediction():
data = pd.read_json(TEST_DATA)
request_data = request.get_data()
print(request_data)
print(type(request_data))
if isinstance(request_data, bytes):
print("Data is of type bytes")
request_data = request_data.decode("utf-8")
print(request_data)
line = json.loads(request_data)['line']
data_test = data.transpose()
X = data_test.drop(data_test.loc[:, 'Line':'# Letter'].columns, axis = 1)
X_test = X.iloc[int(line),:].values.reshape(1, -1)
clf_lda = load(MODEL_PATH_LDA)
prediction_lda = clf_lda.predict(X_test)
return {'prediction LDA': int(prediction_lda)}
if __name__ == "__main__":
app.run(debug=True, host='0.0.0.0', port = 5000)
Creación del contenedor
Puede utilizar cualquier imagen de OCI Container Registry. A continuación se muestra un archivo Dockerfile de ejemplo que utiliza el servidor Flask:
FROM jupyter/scipy-notebook
USER root
RUN \
apt-get update && \
apt-get -y install curl
ENV WORK_DIRECTORY=/opt/ds/model/deployed_model
ENV MODEL_DIR=$WORK_DIRECTORY/models
RUN mkdir -p $MODEL_DIR
ENV MODEL_FILE_LDA=clf_lda.joblib
COPY requirements.txt /opt/requirements.txt
RUN pip install -r /opt/requirements.txtEl paquete de Curl se debe instalar en la imagen de contenedor para que funcione la política de docker HEALTHCHECK.
Cree un archivo requirements.txt con los siguientes paquetes en el mismo directorio que Dockerfile:
flask
flask-restful
joblibEjecute el comando docker build:
docker build -t ml_flask_app_demo:1.0.0 -f Dockerfile .El tamaño máximo de una imagen de contenedor descomprimida que puede utilizar con despliegues de modelo es de 16 GB. Recuerde que el tamaño de la imagen de contenedor ralentiza el tiempo de aprovisionamiento para el despliegue del modelo porque se extrae de Container Registry. Le recomendamos que utilice las imágenes de contenedor más pequeñas posibles.
Prueba del contenedor
Asegúrese de que el artefacto de modelo y el código de inferencia están en el mismo directorio que el archivo Dockerfile. Ejecute el contenedor en la máquina local. Para hacer referencia a los archivos almacenados en la máquina local, monte el directorio del modelo local en /opt/ds/model/deployed_model:
docker run -p 5000:5000 \
--health-cmd='curl -f http://localhost:5000/health || exit 1' \
--health-interval=30s \
--health-retries=3 \
--health-timeout=3s \
--health-start-period=1m \
--mount type=bind,src=$(pwd),dst=/opt/ds/model/deployed_model \
ml_flask_app_demo:1.0.0 python /opt/ds/model/deployed_model/api.pyEnvíe una solicitud de estado para verificar que el contenedor se está ejecutando dentro de los 10 minutos definidos por el servicio:
curl -vf http://localhost:5000/healthPruebe enviando una solicitud de predicción:
curl -H "Content-type: application/json" -X POST http://localhost:5000/predict --data '{"line" : "12"}'Transferencia del contenedor a OCI Container Registry
Para poder transferir y extraer imágenes de Oracle Cloud Infrastructure Registry (también conocido como Container Registry), debe tener un token de autorización de Oracle Cloud Infrastructure. Solo verá la cadena de token de autenticación al crearla, así que asegúrese de copiar el token de autenticación en una ubicación segura inmediatamente.
- Para ver los detalles en la consola: en la barra de navegación, seleccione el menú Perfil y, a continuación, seleccione Configuración de usuario o Mi perfil, según la opción que vea.
- En la página Tokens de autenticación, seleccione Generar token.
- Introduzca una descripción fácil de recordar para el token de autenticación. Evite introducir información confidencial.
- Seleccione Generar token. Aparece el nuevo token de autenticación.
- Copie el token de autenticación inmediatamente en una ubicación segura donde pueda recuperarlo más tarde. No volverá a ver el token de autenticación en la consola.
- Cierre el cuadro de diálogo Generar token.
- Abra una ventana de terminal en la máquina local.
- Conéctese a Container Registry para crear, ejecutar, probar, etiquetar y transferir la imagen de contenedor.
docker login -u '<tenant-namespace>/<username>' <region>.ocir.io - Etiquete la imagen de contenedor local:
docker tag <local_image_name>:<local_version> <region>.ocir.io/<tenancy_ocir_namespace>/<repository>:<version> - Ejecute Push en la imagen de contenedor:
docker push <region>.ocir.io/<tenancy>/byoc:1.0Nota
Asegúrese de que el recurso de despliegue de modelo tiene una política para la entidad de recurso para que pueda leer la imagen desde OCI Registry desde el compartimento en el que ha almacenado la imagen. Otorgar acceso de despliegue de modelo a un contenedor personalizado mediante la entidad de recurso
Está listo para utilizar esta imagen de contenedor con la opción BYOC al crear un despliegue de modelo.
Los despliegues del modelo BYOC no soportan la extracción de imágenes de contenedor entre regiones. Por ejemplo, al ejecutar un despliegue de modelo BYOC en una región IAD (Ashburn), no puede extraer imágenes de contenedor de OCIR (Oracle Cloud Container Registry) en la región PHX (Phoenix).
Comportamiento de operación de actualización de BYOC
Las operaciones de actualización de BYOC son actualizaciones parciales de tipo de fusión superficial.
Un campo de nivel superior con capacidad de escritura se debe reemplazar por completo cuando aparece definido en el contenido de la solicitud y, de lo contrario, se debe mantener sin cambios. Por ejemplo, para un recurso como el siguiente:
{
"environmentConfigurationDetails": {
"environmentConfigurationType": "OCIR_CONTAINER",
"serverPort": 5454,
"image": "iad.ocir.io/testtenancy/md_byoc_ref_iris_data:1.0.1",
"imageDigest": "sha256:a9c8468cb671929aec7ad947b9dccd6fe8e6d77f7bcecfe2e10e1c935a88c2a5",
"environmentVariables": {
"a": "b",
"c": "d",
"e": "f"
},
"entrypoint": [ "python", "-m", "uvicorn", "a/model/server:app", "--port", "5000","--host","0.0.0.0"]
"cmd": ["param1"]
}Una actualización correcta con lo siguiente:
{
"environmentConfigurationDetails": {
"serverPort": 2000,
"environmentVariables": {"x":"y"},
"entrypoint": []
}
}Da como resultado un estado en el que serverPort y environmentVariables se sobrescriben con el contenido de la actualización (incluida la destrucción de datos presentes anteriormente en campos profundos que están ausentes en el contenido de la actualización). image se mantiene sin cambios porque no aparece en el contenido de actualización y entrypoint se borra mediante una lista vacía explícita:
{
"environmentConfigurationDetails": {
"environmentConfigurationType": "OCIR_CONTAINER",
"serverPort": 2000,
"image": "iad.ocir.io/testtenancy/md_byoc_ref_iris_data:1.0.1",
"imageDigest": "sha256:a9c8468cb671929aec7ad947b9dccd6fe8e6d77f7bcecfe2e10e1c935a88c2a5",
"environmentVariables": {"x": "y"},
"entrypoint": []
"cmd": ["param1"]
}Una actualización correcta con { "environmentConfigurationDetails": null or {} } no provoca que se sobrescriba nada. Una sustitución completa en el nivel superior borra todos los valores que no están en el contenido de la solicitud, así que evite eso. Todos los campos son opcionales en el objeto de actualización, por lo que si no proporciona la imagen, no se debe anular la definición de la imagen en el despliegue. Data Science realiza una sustitución en los campos de segundo nivel solo si no son nulos.
Si no se define un campo en el objeto de solicitud (se transfiere un valor nulo), Data Science no tendrá en cuenta ese campo para buscar la diferencia y sustituirlo por el valor de campo existente.
Para restablecer un valor de cualquier campo, pase un objeto vacío. Para los campos de tipo de lista y asignación, Data Science puede aceptar una lista vacía ([]) o una asignación ({}) como indicación para borrar los valores. En cualquier caso, null no significa borrar los valores. Sin embargo, siempre puede cambiar el valor a otra cosa. Para utilizar un puerto por defecto y anular la definición del valor de campo para él, defina explícitamente el puerto por defecto.
La actualización de los campos de lista y mapa es una sustitución completa. Data Science no busca valores individuales en los objetos.
Para imágenes y resúmenes, Data Science no permite borrar el valor.
Despliegue con un contenedor de Triton Inference Server
NVIDIA Triton Inference Server optimiza y estandariza la inferencia de IA al permitir a los equipos implementar, ejecutar y escalar modelos de IA entrenados desde cualquier marco en cualquier infraestructura basada en GPU o CPU.
Algunas características clave de Tritón son:
- Ejecución simultánea de modelos: la capacidad de servir varios modelos de aprendizaje automático simultáneamente. Esta función es útil cuando varios modelos se deben desplegar y gestionar juntos en un solo sistema.
- Lote dinámico: permite al servidor agrupar solicitudes de forma dinámica en función de la carga de trabajo para ayudar a mejorar el rendimiento.
El despliegue de modelos tiene soporte especial para el Triton Inference Server de NVIDIA. Puede desplegar una imagen de Triton existente del catálogo de contenedores de NVIDIA y el despliegue del modelo garantiza que las interfaces de Triton coincidan sin necesidad de cambiar nada en el contenedor mediante la siguiente variable de entorno al crear el despliegue del modelo:
CONTAINER_TYPE = TRITONHay disponible un ejemplo completo documentado sobre cómo desplegar modelos ONNX en Triton en el repositorio de despliegue de modelos de Data Science GitHub.