異常検出アルゴリズム
異常検出では、機械学習(ML)アルゴリズムを使用してパターンを学習し、データセットから異常を検出します。
単変量アルゴリズムは、1つのシグナルまたはセンサーのみで動作するアルゴリズムです。通常、これらのアルゴリズムは、センサーまたは信号内の異常を識別するために使用されるシグナルごとに1つのモデルを構築します。異常検出サービスを使用して、センサーまたはシグナルのモデルへの内部的なマッピングを管理することで、データセット内の複数のシグナルの単一モデルをトレーニングします。
デフォルトでは、モデル・トレーニングは単変量アルゴリズムを使用して行われます。ただし、異常検出APIを使用してこの動作をオーバーライドできます。
単変量アルゴリズム
異常検出は、単変量データセット内の異常を識別するのに役立ちます。
トレーニングおよびテスト・データには、タイムスタンプと、通常はセンサーまたはシグナルの読取りを表すその他の数値属性のみを含めることができます。
-
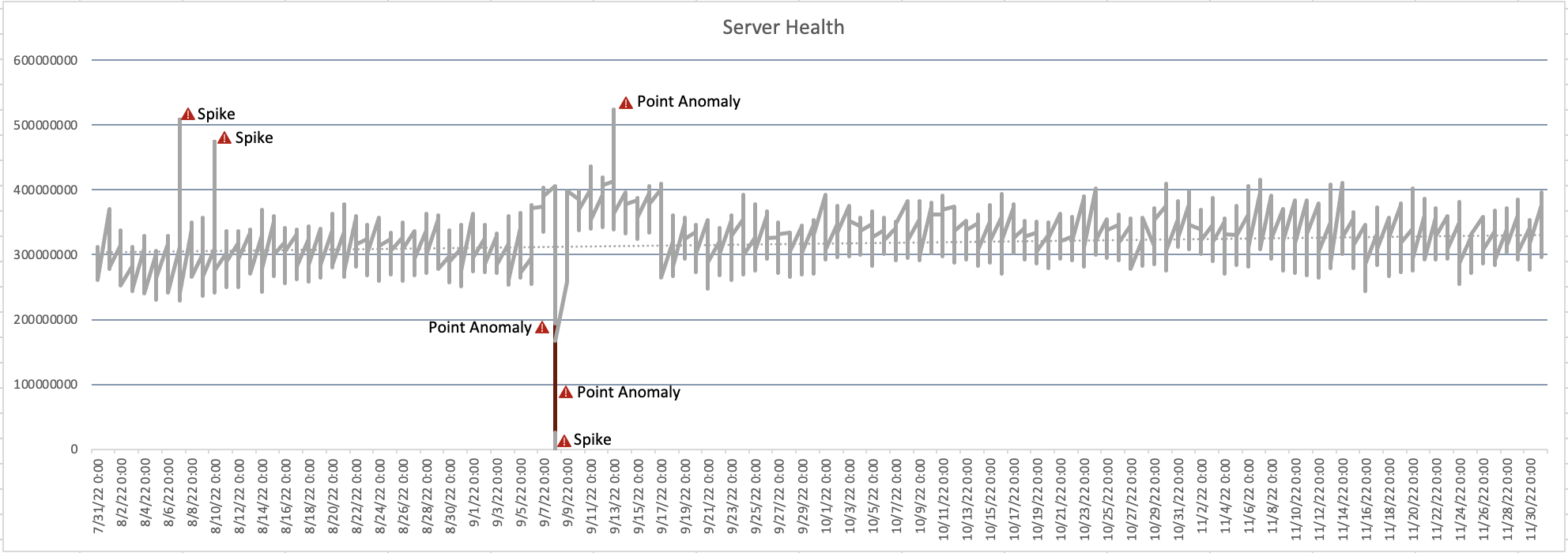
異常検出で正確に識別できる単変量時系列パターンのタイプ:
-
季節パターン
-
均一トレンド
-
継続的に増加および減少する線形トレンド・データセット
-
-
異常検出で正確に識別できる異常のタイプ:
-
ポイント異常
-
スパイク
-
単変量アルゴリズムは、シグナルごとに1つのモデルを構築し、最適なクラシックMLアルゴリズムの1つです。MSET2によって相関が低いと見なされるシグナルは、このアルゴリズムを使用して自動的に単変量として処理されます。
単変量アルゴリズムはスタンドアロンではなく、同じデータ入力書式を持つ既存の多変量ベースAPIを使用します。各単変量シグナルの単変量モデルは、独立して構築、最適化および保存されます。また、モデルは個別に推論に使用されます。
- 機能
-
時系列パターンを考慮してシグナルの異常を検出し、ポイント異常またはコンテキスト異常に対して機能します。
- 要件
-
-
検出データセットは異常なデータ・ポイントを持つことができます。
- 数値のみを含むトレーニングおよび推論データセット。カテゴリ値または公称値はサポートされていません。
- このアルゴリズムは、ウィンドウベースの機能設計アプローチを使用します。パターンを学習したり異常を検出するには、実際のトレーニングまたはデータを検出する前に、1つのウィンドウ・サイズのデータが必要です。タイムスタンプの最小合計数は80です。
- トレーニング・データセットには、様々な通常のビジネス・シナリオがすべて含まれています。たとえば、トレーニング部分には少なくとも1つのビジネス・サイクルがあります。
-
- ユース・ケース
-
業界全体で単変量異常検出のユース・ケースが見つかりました。単変量シグナルは他のシグナルとは相関していないため、個別に監視する必要があります。
- 制限
-
- アルゴリズムは一度に1つのシグナルだけを処理するため、複数のシグナル間の集合的な異常は対処されません。
- 単変量アルゴリズムはスタンドアロンではなく、同じデータ入力書式を持つ既存の多変量ベースAPIを使用します。
多変量アルゴリズム
多変量アルゴリズムは、多変量データセット内の異常を識別するのに役立ちます。
異常検出は、データセットを自動的に分析し、多変量機械学習モデルまたはシグナル間の相関性を考慮して構築します。異常検出は、大量のシグナルを持つ複雑なシステムをモニターするのに役立ちます。
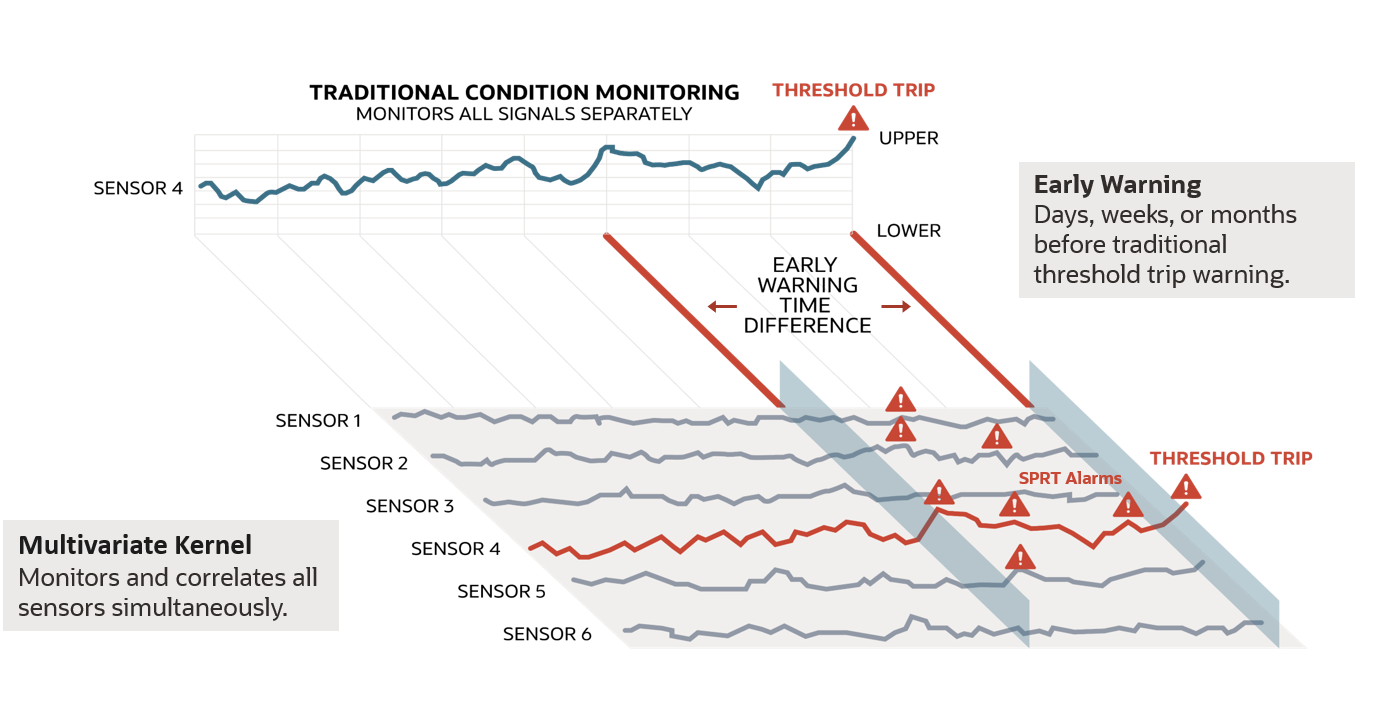
異常検出サービスでは、メイン・カーネルとしてMSET2を使用して、データセットから多変量時系列異常を検出します。MSET2は、次の3つの手法を表します:
-
多変量状態推定手法(MSET)
-
逐次確率比検定(SPRT)
-
インテリジェント・データ前処理(IDP)
これらの手法はすべてOracle Labsが発明しました。MSET2アルゴリズムは、いくつかの業界で予後分析に正常に使用されています。
- 機能
-
これは、相関性の高い数値シグナルを持つ多変量データセット内のポイント異常、コンテキスト異常および集合異常を検出するために機能します。中程度のレベルの欠落値があるデータセットを処理でき、推定値が提供されます。
- 要件
-
- トレーニングおよび推論データセットには、数値のみを含めることができます。カテゴリ値または公称値はサポートされていません。
- シグナル間の相関は比較的高いです。たとえば、1つのシグナルと残りのシグナル間のペアワイズ・ピアソン相関の平均は0.1以上です。カーネルは相関の低いシグナルを除外し、単変量モデリングで処理します。
- トレーニング・データセットは異常がないことが必要です。たとえば、データセットには、通常のビジネス・シナリオと、発生頻度の低い異常イベントがないデータ値が含まれています。
- トレーニング・データセットには、様々な通常のビジネス・シナリオがすべて含まれています。たとえば、トレーニング部分には少なくとも1つのビジネス・サイクルがあります。通常のビジネス・パターンが欠落すると、推測中に誤検出が発生する可能性があります。
- ユース・ケース
-
MSET2の一般的なユース・ケースは、製造、IoT、輸送、石油およびガス、エネルギー業界にあります。これは、データが信号システムまたはアセットからのものであり、信号の相関性が高いためです。
- 制限
-
数値、高度に相関していない、または時系列ベースでないデータセットを使用するユースケースでは、MSET2を使用して異常を検出しないでください。