クラウドSQL問合せ処理
問合せは、Oracle Big Data Serviceクラスタ上のセルを使用して処理されます。
ビッグ・データ・ソースのスマート・スキャンについて
Oracle外部表には従来の索引はありません。これらの外部表に対する問合せには通常、全表スキャンが必要です。HadoopクラスタのDataNode上にあるOracle Cloud SQL処理エージェントは、スマート・スキャン機能(フィルタ述語オフロードなど)をOracle外部表に拡張します。Oracle Exadata Database Machineでは、しばらくの間、スマート・スキャンを使用して、問合せ結果がデータベース・レイヤーに戻される前に、ストレージ・レイヤーの列および述語のフィルタリングを実行していました。クラウドSQLでは、スマート・スキャンはHadoopサーバーでローカルに実行される最終的なフィルタリング・パスです。これによって、リクエストされた要素のみがクラウドSQL問合せサーバーに送信されるようにできます。Hadoop DataNodeで実行されているクラウドSQLセルは、CSVテキスト、Avro、Parquetなど、HDFSの様々なデータ・フォーマットに対してスマート・スキャンを実行できます。
スマート・スキャンをこのように実装すると、Hadoopクラスタの大規模なパラレル処理能力を利用して、データが当初の状態からフィルタされます。関連のないデータの膨大な部分(全体の99パーセントまで)を先制的に破棄することもできます。これには、次のような利点があります:
-
クラスタとデータベースの間のデータの移動やネットワーク・トラフィックが大幅に削減されます。
-
Oracle Databaseサーバーに返される結果セットがはるかに小さくなります。
-
可能な場合、スケーラビリティとクラスタ処理を利用して、データを集計します。
問合せ結果を返す速度が大幅に向上します。これは、ネットワーク上のトラフィックが減り、Oracle Databaseの負荷が減ったことが直接的にもたらした結果です。
ストレージ索引について
HDFSに格納されているデータの場合、Oracle Cloud SQLはOracle Databaseに透過的なストレージ索引を自動的に保持します。ストレージ索引には、HDFSに格納されているデータのハード・ディスクへのデータ分散のサマリーが含まれます。ストレージ索引により、I/O操作のコストと、フラット・ファイルのデータをOracle Databaseブロックに変換するCPUコストが削減されます。ストレージ索引は否定の索引と考えることができます。データがデータ・ブロック内に含まれていないことがスマート・スキャンに通知され、スマート・スキャンはそのブロックの読取りをスキップできます。これにより、I/Oを大幅に回避できます。
ストレージ索引は、HDFSに基づき、ORACLE_HDFSドライバまたはORACLE_HIVEドライバを使用して作成されている外部表にのみ使用できます。ストレージ索引は、Apache HBaseやOracle NoSQLなどのStorageHandlerを使用する外部表では使用できません。
ストレージ索引はメモリー内リージョン索引のコレクションであり、各リージョン索引には最大32列のサマリーが格納されます。分割ごとにリージョン索引が1つ存在します。1つのリージョン索引に格納されるコンテンツは、他のリージョン索引からは独立しています。これにより、スケーラビリティが向上し、ラッチ競合が回避されます。
ストレージ索引では、各リージョン索引のリージョンの列の最小値および最大値が保持されます。最小値および最大値は不要なI/Oを回避するために使用され、これはI/Oフィルタリングとも呼ばれます。V$SYSSTATビューに表示されるストレージ索引統計別に保存されたセルのXTグラニュルI/Oバイト数は、ストレージ索引を使用して保存されたI/Oのバイト数を示しています。
次の比較を使用した問合せは、ストレージ索引によって向上します:
-
Equality (=)
-
等しくない(<、!= または>)
-
以下(<=)
-
以上(>=)
-
IS NULL
-
NULLでない
ストレージ索引は、Oracle Cloud SQLサービスが、リージョン内の列の最大値よりも大きいか最小値よりも小さい比較述語を持つ問合せを受信した後、自動的に作成されます。
-
WHERE問合せ句に頻繁に出現する列に基づいて表の行を順序付けすることで、ストレージ索引の効率を高めることができます。 -
ストレージ索引は、すべての非言語データ型と、非言語索引に類似した言語データ型で動作します。
ストレージ索引を使用したディスクI/Oの回避
次の図は、表とリージョン索引を示しています。表の列Bの値の範囲は1から8までです。1つのリージョン索引には最小値1と最大値5が格納されています。もう1つのリージョン索引には、最小値3と最大値8が格納されています。
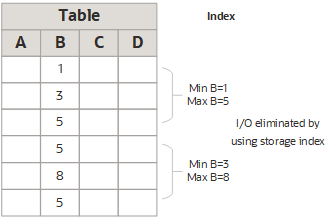
WHERE句に一致しないため、ディスクI/Oが回避されます。SELECT *
FROM TABLE
WHERE B < 2;ストレージ索引を使用した結合パフォーマンスの向上
ストレージ索引を使用すると、表の結合で不要なI/O操作をスキップできます。たとえば、次の問合せはI/O操作を実行し、ブルーム・フィルタをファクト表の最初のブロックのみに適用します。ブルーム・フィルタは、結合パフォーマンスを向上させる鍵となります。例では、ファクト表ではなくディメンション表に述語があります。ブルーム・フィルタはdim.name=Hard driveに基づいて作成され、このフィルタがファクト表に適用されます。このため、フィルタがディメンション表にある場合でも、ディメンション問合せの結果に基づいて、そのソース(Hadoop)でデータをフィルタできます。これにより、ストレージ索引のような最適化も可能になります。
SELECT count(*)
FROM fact, dimension dim
WHERE fact.m=dim.m and dim.product="Hard drive";
ファクト表の2つ目のブロックのI/Oは、最小値/最大値の範囲(5,8)がブルーム・フィルタに存在しないため、ストレージ索引によって完全に回避されます。
述語プッシュダウンについて
多くのビッグ・データ・システムでは、ファイル・タイプ自体を使用するか(たとえば、Apache Parquet)、HiveのパーティショニングおよびStorageHandler APIを使用して、ある程度の述語オフロードがサポートされています。Oracle Cloud SQLでは、Oracle Databaseからサポートしているシステムに述語をプッシュすることで、これらのオフロード機能を利用しています。たとえば、述語プッシュダウンによる次の自動動作を可能にします:
-
パーティション列に対するフィルタ述語に基づいて、パーティショニングされたHive表に対する問合せがプルーニングされます。
-
Apache ParquetおよびApache ORCファイルに対する問合せでは、これらのファイル・フォーマットに含まれている内部索引に似た構造に対して述語をテストすることで、I/Oが削減されます。
ノート
Parquetファイルは、HiveまたはSparkを使用して作成する必要があります。Apache Impalaを使用してParquetファイルを作成すると、述語プッシュダウンを行う場合に必要な統計が欠落します。 -
Oracle NoSQL DatabaseまたはApache HBaseに対する問合せでは、SARGable述語を使用して、リモート・データ・ストア内のデータのサブスキャンを促進します。
述語プッシュダウンを有効にするために必要なデータ型
述語プッシュダウンでは、Hiveデータ型とOracleデータ型との間でなんらかのマッピングが必要になります。これらのマッピングについては、次の表で説明します。
| Hiveデータ型 | Oracleデータ型へのマッピング |
|---|---|
|
CHAR(m) |
CHAR(n), VARCHAR2(n) ここでnはm以上 |
|
VARCHAR(m) |
CHAR(n), VARCHAR2(n) ここでnはm以上。 |
|
string |
CHAR(n)、VARCHAR2(n) |
|
DATE |
DATE |
|
タイムスタンプ |
TIMESTAMP(9) Hive TIMESTAMPには、ナノ秒(9桁の小数秒)があります。 |
|
TINYINT |
NUMBER(3)を推奨しますが、NUMBERまたはnを任意の値にしたNUMBER(n)も有効です。 |
|
SMALLINT |
NUMBER(5)を推奨しますが、NUMBERまたはnを任意の値にしたNUMBER(n)も有効です。 |
|
INT |
NUMBER(10)を推奨しますが、NUMBERまたはnを任意の値にしたNUMBER(n)も有効です。 |
|
ビギン |
NUMBER(19)を推奨しますが、NUMBERまたはnを任意の値にしたNUMBER(n)も有効です。 |
|
DECIMAL(m) |
NUMBER(n)を推奨します(ここでm = n)が、NUMBERまたはnを任意の値にしたNUMBER(n)も有効です。 |
|
フローティング |
BINARY_FLOAT |
|
ダブル |
BINARY_DOUBLE |
|
バイナリ |
RAW(n) |
|
ブール |
CHAR(n), VARCHAR2(n)。ここで、nは5以上、値はTRUE、FALSE |
|
ブール |
NUMBER(1)を推奨しますが、NUMBERまたはnを任意の値にしたNUMBER(n)も有効です。値0 (false)、1 (true)。 |
キャラクタ・ラージ・オブジェクト(CLOB)処理のプッシュダウンについて
Hadoopデータに対する問合せには、何百万ものレコードを伴う可能性のある大きなオブジェクトの処理が含まれる場合があります。このようなオブジェクトをフィルタリングおよび解析のためにOracle Databaseに戻すのは非効率的です。Oracle Cloud SQLでは、CLOB処理をHadoopクラスタ上の独自の処理セルにプッシュすることで、パフォーマンスが大幅に向上します。Hadoopでのフィルタリングにより、Oracle Databaseに戻される行数が減少します。解析により、フィルタリングされた各行の列から戻されるデータ量が減少します。
自分のニーズにあわせて、CLOB処理のプッシュを無効化または再有効化できます。
現在、この機能はCLOBデータを戻すJSON式にのみ適用されます。ストレージ・レイヤー評価に適したJSONフィルタ式では、JSON_VALUEおよびJSON_QUERYというように構文が簡素化されています。
今後のリリースでは、これと同じサポートが他のCLOB型(substrやinstrなど)に加えてBLOBデータにも提供される予定です。
クラウドSQLでは、次のサイズ制約内でCLOBの処理をHadoopにプッシュ・ダウンできます:
-
フィルタできるCLOB列のサイズは最大1MBです。
ストレージ・サーバーでの評価に利用できるデータの実際の量は、使用する文字セットに応じて異なることがあります。
-
解析できる列は最大32KBです。
この制限は、CLOBデータ型のストレージからの選択リスト・プロジェクションを対象とします。
列サイズがこの2つの値を超えた場合にのみ、処理がOracle Databaseにフォールバックします。
JSONドキュメント処理
{"ponumber":9764,"reference":"LSMITH-20141017","requestor":"Lindsey Smith","email": "Lindsey@myco.com", "company":"myco" …}CREATE TABLE POS_DATA
( pos_info CLOB )
ORGANIZATION EXTERNAL
( TYPE ORACLE_HDFS
DEFAULT DIRECTORY DEFAULT_DIR
LOCATION ('/data/pos/*')
)
REJECT LIMIT UNLIMITED;SELECT p.pos_info.email, p.pos_info.requestor
FROM POS_DATA p
WHERE p.pos_info.company='myco'
前述の問合せの例では、次の2つの方法でデータ消去を最適化しています:
-
データをHadoopクラスタのクラウドSQLセルでフィルタします。会社
mycoに関連するレコードのみを解析します(また、解析後、これらのレコードから選択したデータのみをデータベースに返します)。 -
クラスタ内のクラウドSQLセルは、フィルタされたレコード・セットを解析し、各レコードから、リクエストされた2つの属性(
p.pos_info.emailおよびp.pos_info.requestor)の値のみをデータベースに返します。
次の表に、CLOB処理のプッシュダウンをサポートする例をさらにいくつか示します。プロジェクション(CLOB列の選択側のリファレンス)が32KBのCLOBデータに制限されているのに対して、述語プッシュダウンは1MBのCLOBデータに制限されていることに注意してください。
| 問合せ | コメント |
|---|---|
SELECT count(*) FROM pos_data p WHERE pos_info is json; |
この場合、述語によって、JSONフォーマットに準拠する列のみが返されるようになります。 |
SELECT pos_info FROM pos_data p WHERE pos_info is json; |
前の例と同じ述語ですが、今回はCLOB値を投影するようになっています。 |
SELECT json_value(pos_info, '$.reference') FROM pos_data p WHERE json_value(pos_info, '$.ponumber') > 9000 |
ここで、JSONドキュメントのフィールドに対して述語を発行し、さらにJSON値を実行して、投影したCLOB JSON値上のフィールド「reference」を取得しています。 |
SELECT p.pos_info.reference FROM pos_data p WHERE p.pos_info.ponumber > 9000; |
これは、機能的には前述の例と同じ問合せですが、簡略化された構文で表現しています。 |
SELECT p.pos_info.email FROM po_data p WHERE json_exists(pos_info, '$.requestor') and json_query(pos_info, '$.requestor') is not null; |
この例では、json_existsとjson_queryを述語としても使用できる方法を示しています。 |
集計オフロードについて
Oracle Cloud SQLでは、Oracle In-Memoryテクノロジを使用してCloud SQLセルに集計処理をプッシュ・ダウンします。これにより、クラウドSQLでは、Hadoopクラスタの処理能力を利用して、クラスタ・ノード間で集計を分散できます。
特に中程度の数のサマリー・グループがある場合、パフォーマンスの向上は、オフロードしない集計と比べて非常に速くなる可能性があります。単一表問合せの場合、集計操作は常にオフロードする必要があります。
クラウドSQLセルは、単一表集計および複数表集計(たとえば、ファクト表に結合するディメンション表)をサポートします。複数表集計の場合、Oracle Databaseでは、キー・ベクターが集計プロセスのセルにプッシュされるキー・ベクター変換最適化を使用します。この変換タイプは、ビジネス問合せで一般的な、標準的な集計演算子(SUM、MIN、MAX、COUNTなど)を使用するスター結合SQL問合せに有用です。
ベクター変換問合せは、結合にブルーム・フィルタを使用する、より効率的な問合せです。ベクター変換された問合せをクラウドSQLセルで使用する場合、問合せ内の結合のパフォーマンスは、集計に使用される行のフィルタ処理をオフロードする機能によって向上します。この最適化中の問合せ計画にKEY VECTOR USE操作があることがわかります。
クラウドSQLセルでは、グループ化列(キー・ベクター)をクラウドSQLストレージ索引に適用することにより、ベクター変換された問合せの処理効率が向上します。
-
述語がありません
実行計画にSYS_OP_VECTOR_GROUP_BY述語がない場合、集計オフロードに影響します。次の理由により、述語が欠落する可能性があります:-
表スキャンとグループ化行ソースの間に、許可されていない介在する行ソースがある。
-
表スキャンで行セットが生成されない。
-
オフロードできない式またはデータ型が問合せに含まれている。
-
ベクター・グループ化が手動で無効になっている。
-
表スキャンの表または構成で、集計オフロードによる向上が期待されていない。
-
-
スマート・スキャンがありません
cell interconnect bytes returned by XT smart scanおよびcell XT granules requested for predicate offload統計が使用可能である必要があります。
-
キー・ベクターがありません
セルに送信されるデータに対する制限は1MBです。このしきい値を超えた場合、問合せはインテリジェントなキー・ベクター・フィルタリングの利点を得ることができますが、オフロードされた集計の利点は必ずしも得られません。この条件は、キー・ベクター・ライト・モードと呼ばれます。サイズが大きいために、一部のキー・ベクターは完全にはオフロードされません。これらは、集計オフロードをサポートしないキー・ベクターとともにライト・モードでオフロードされます。キー・ベクターは、ライト・モードでは完全にはシリアライズされません。キー・ベクターがライト・モードでオフロードされるときは、ベクター・グループ化オフロードは無効になります。
クラウドSQL統計について
Oracle Cloud SQLには、パフォーマンス分析にデータを提供できる数多くの統計が用意されています。
5つの主要なセルのXTおよびストレージ索引統計
問合せがオフロード可能な場合、次のXT関連の統計が、どのようなI/Oの節約をオフロードおよびスマート・スキャンから期待できるかを判断するために役立ちます。
-
述語のオフロードが要求されたセルXTグラニュル
リクエストされるグラニュルの数は、HDFSブロック・サイズ、Hadoopデータ・ソースの分割可能性、Hiveパーティションの消去の有効性など、多数の要因によって異なります。
-
述語オフロードでリクエストされたセルXTグラニュル・バイト
スキャンでリクエストされたバイト数。これは、Hiveパーティションの消去後およびストレージ索引の評価前に調査されるHadoop上のデータのサイズです。
-
セル相互接続バイト数がXTスマートスキャンによって返されました
XTスマート・スキャンによってOracle Databaseに返されたI/Oのバイト数。
-
セルXTグラニュル述語のオフロード・リトライ
DataNode上で実行されているクラウドSQLプロセスが、リクエストされたアクションを完了できなかった回数。クラウドSQLは、データのレプリカを持つ他のDataNode上で、失敗したリクエストを自動的に再試行します。再試行の値はゼロになります。
-
セルXTグラニュルIOバイトがストレージ索引に保存されました
ストレージ・セル・レベルでストレージ索引によってフィルタで除外されたバイト数。これは、ストレージ索引によって提供される情報に基づいて、スキャンされなかったデータです。
これらの統計は、次のように、問合せを実行する前と実行した後に確認できます。この例は、問合せを実行する前の、nullの値を示しています。
SQL> SELECT sn.name,ms.value
FROM V$MYSTAT ms, V$STATNAME sn
WHERE ms.STATISTIC#=sn.STATISTIC# AND sn.name LIKE '%XT%';
NAME VALUE
----------------------------------------------------- -----
cell XT granules requested for predicate offload 0
cell XT granule bytes requested for predicate offload 0
cell interconnect bytes returned by XT smart scan 0
cell XT granule predicate offload retries 0
cell XT granule IO bytes saved by storage index 0 これらの統計の一部またはすべてを問合せの実行後にチェックして、次のように、問合せの有効性をテストできます:
SQL> SELECT n.name, round(s.value/1024/1024)
FROM v$mystat s, v$statname n
WHERE s.statistic# IN (462,463)
AND s.statistic# = n.statistic#;
cell XT granule bytes requested for predicate offload 32768
cell interconnect bytes returned by XT smart scan 325つの集計オフロード統計
次の統計は、集計オフロードのパフォーマンスを分析する際に役立ちます。
-
vector group by operations sent to cell
集計をセルにオフロードできる回数。
-
vector group by演算がセルに送信されません。
大きなワイヤフレームのためにオフロードされなかったスキャンの数。
-
vector group by rows processed on cell
セルで集計された行の数。
-
vector group by rows returned by cell
セルによって返された集計行の数。
-
vector group by rowsets processed onセル
セルで集計された行セットの数。
これらの統計は、次のような問合せを実行することで確認できます:
SQL> SELECT count(*) FROM bdsql_parq.web_sales;
COUNT(*)
----------
287301291
SQL> SELECT substr(n.name, 0,60) name, u.value
FROM v$statname n, v$mystat u
WHERE ((n.name LIKE 'key vector%') OR
(n.name LIKE 'vector group by%') OR
(n.name LIKE 'vector encoded%') OR
(n.name LIKE '%XT%') OR
(n.name LIKE 'IM %' AND n.name NOT LIKE '%spare%'))
AND u.sid=userenv('SID')
AND n.STATISTIC# = u.STATISTIC#
AND u.value > 0;
NAME VALUE
----------------------------------------------------- -----
cell XT granules requested for predicate offload 808
cell XT granule bytes requested for predicate offload 2.5833E+10
cell interconnect bytes returned by XT smart scan 6903552
vector group by operations sent to cell 1
vector group by rows processed on cell 287301291
vector group by rows returned by cell 808
9つのキー・ベクター統計
次の統計は、セルに送信されたキー・ベクターの有効性を分析するために役立ちます。
-
キー・ベクターがセルに送信されました
セルにオフロードされたキー・ベクターの数。
-
key vector filtered on cell
セルのキー・ベクターによってフィルタで除外された行の数。
-
キー・ベクトルがセルでプローブされました
セルのキー・ベクターによってテストされた行の数。
-
キー・ベクトル行が値によって処理されました
値を使用して処理された結合キーの数。
-
キー・ベクトル行がコードで処理されました
ディクショナリ・コードを使用して処理された結合キーの数。
-
キー・ベクトル行がフィルタされました
スキップ・ビットのためにスキップされた結合キーの数。
-
キー・ベクトルの直列化(ライト・モード、セル)
フォーマットまたはサイズのためにキー・ベクターがエンコードされなかった回数。
-
鍵ベクトルが、割り当て制限のためにliteモードのセルに送信されました
1MBのメタデータ割当てのために非完全フィルタリングのセルにオフロードされたキー・ベクターの数。
-
キー・ベクトル・フィルタが作成されました
キー・ベクターはセルに送信されませんでしたが、(ブルーム・フィルタに似た) efilterが送信されました。
これらの統計は、次のような問合せを実行することで確認できます:
SELECT substr(n.name, 0,60) name, u.value
FROM v$statname n, v$mystat u
WHERE ((n.name LIKE 'key vector%') OR
(n.name LIKE 'vector group by%') OR
(n.name LIKE 'vector encoded%') OR
(n.name LIKE '%XT%'))
AND u.sid=userenv('SID')
AND n.STATISTIC# = u.STATISTIC#
NAME VALUE
----------------------------------------------------- -----
cell XT granules requested for predicate offload 250
cell XT granule bytes requested for predicate offload 61,112,831,993
cell interconnect bytes returned by XT smart scan 193,282,128
key vector rows processed by value 14,156,958
key vector rows filtered 9,620,606
key vector filtered on cell 273,144,333
key vector probed on cell 287,301,291
key vectors sent to cell 1
key vectors sent to cell in lite mode due to quota 1
key vector serializations in lite mode for cell 1
key vector efilters created 1
The Data Warehouse Insiderで公開されているブログBig Data SQL Quick Startでは、これらの統計を使用してビッグ・データSQLのパフォーマンスを分析する方法が提供されています。クラウドSQLとビッグ・データSQLは、同じ基礎となるテクノロジを共有しているため、同じ最適化ルールが適用されます。Part 2、Part 7およびPart 10を参照してください。