データ・フローの概要
データ・フローについて、およびそれを使用してApache Spark アプリケーションの出力を簡単に作成、共有、実行および表示する方法を学習します。
Oracle Cloud Infrastructureデータ・フローとは
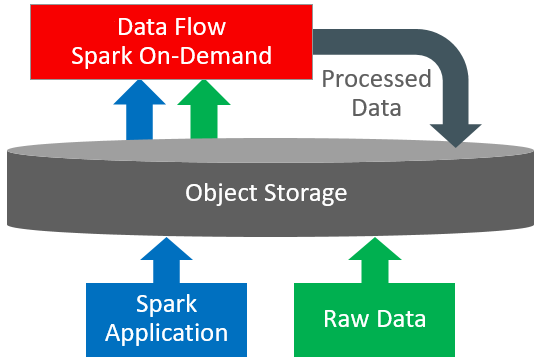
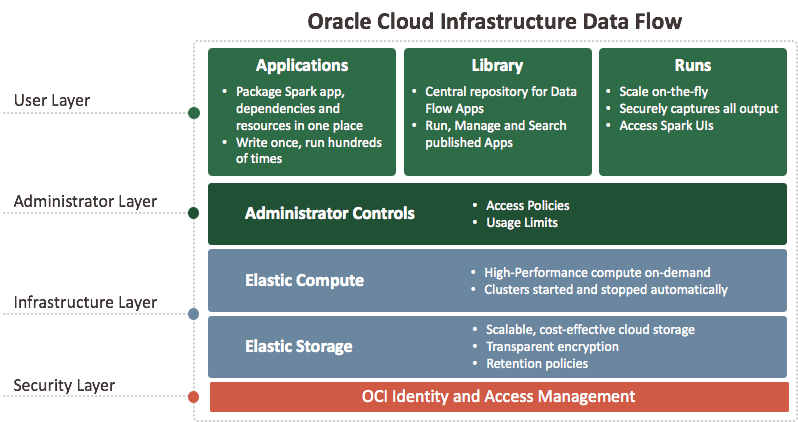
データ・フローは、豊富なユーザー・インタフェースを備えたクラウドベースのサーバーレス・プラットフォームです。これにより、Spark開発者およびデータ・サイエンティストは、クラスタの必要性、オペレーション・チームまたは高度に特化したSparkの知識がなくても、任意のスケールでSparkジョブを作成、編集および実行できます。サーバーレスとは、ユーザーがデプロイまたは管理するインフラストラクチャがないことを意味します。これは、完全にREST APIによって駆動されるため、アプリケーションやワークフローとの統合が容易です。データ・フローは、このREST APIを使用して制御できます。データ・フローはCLIから実行できます。データ・フローのコマンドは、Oracle Cloud Infrastructureのコマンドライン・インタフェースの一部として使用できます。可能なこと:
Apache Sparkデータ・ソースに接続する。
再利用可能なApache Sparkアプリケーションを作成する。
Apache Sparkジョブを数秒で起動する。
SQL、Python、Java、Scalaまたはspark-submitを使用してApache Sparkアプリケーションを作成する。
単一のプラットフォームからすべてのApache Sparkアプリケーションを管理する。
データ・センターのクラウドまたはオンプレミスのデータを処理する。
高度なビッグ・データのアプリケーションに簡単に組み入れることができる、ビッグ・データの構築ブロックを作成する。