Set Up Data Flow
Before you can create, manage and run applications in Data Flow, the tenant administrator (or any user with elevated privileges to create buckets and change policies in IAM) must create groups, a compartment, storage, and associated policies in IAM.
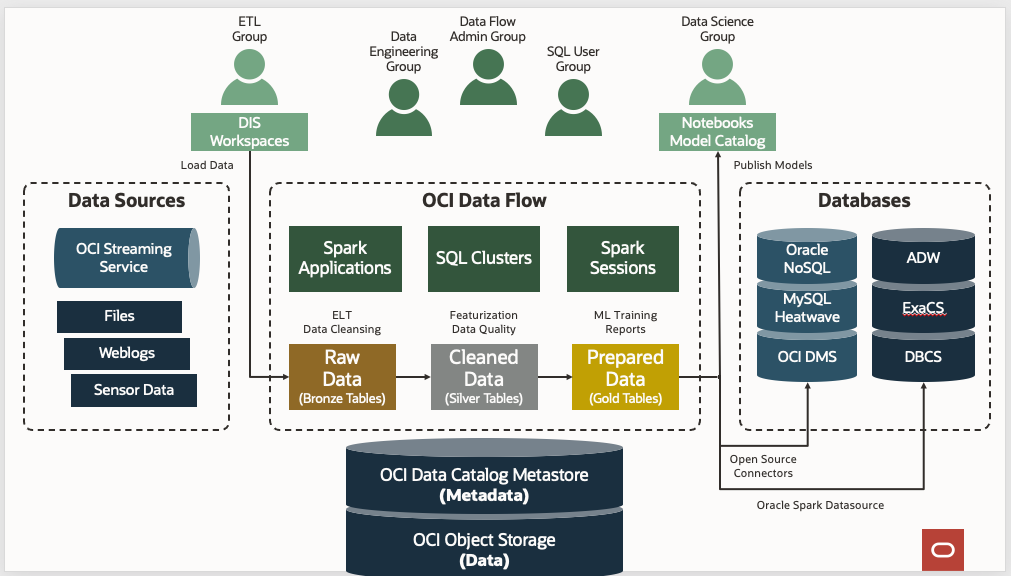 These are the steps required to set up Data Flow:
These are the steps required to set up Data Flow:- Setting up identity groups.
- Setting up the compartment and object storage buckets.
- Setting up Identity and Access Management policies
Set Up Identity Groups
As a general practice, categorize your Data Flow users into three groups for clear separation of their use cases and privilege level.
Create the following three groups in your identity service, and add users to each group:
- dataflow-admins
- dataflow-data-engineers
- dataflow-sql-users
- dataflow-admins
- The users in this group are administrators or super-users of the Data Flow. They have privileges to take any action on Data Flow or to set up and manage different resources related to Data Flow. They manage Applications owned by other users and Runs started by any user within their tenancy. Dataflow-admins don't have need of administration access to the Spark clusters provisioned on-demand by Data Flow, as those clusters are fully managed by Data Flow.
- dataflow-data-engineers
- The users in this group have privilege to manage and run Data Flow Applications and Runs for their data engineering jobs. For example, running Extract Transform Load (ETL) jobs in Data Flow's on-demand serverless Spark clusters. The users in this group don't have nor need administration access to the Spark clusters provisioned on-demand by Data Flow, as those clusters are fully managed by Data Flow.
- dataflow-sql-users
- The users in this group have privilege to run interactive SQL queries by connecting to Data Flow Interactive SQL clusters over JDBC or ODBC.
Setting Up the Compartment and Object Storage Buckets
Follow these steps to create a compartment and Object Storage buckets for Data Flow.