ジョブ
データ・サイエンス・ジョブにより、データ準備、モデル・トレーニング、ハイパーパラメータ・チューニング、バッチ推論などのユース・ケースを適用できるカスタム・タスクが可能になります。
ジョブを使用すると、次のことができます:
-
JupyterLabのノートブック・セッションの外部で機械学習(ML)またはデータ・サイエンス・タスクを実行します。
-
個別のデータ・サイエンスおよび機械学習タスクを、再利用可能な実行可能な操作として操作可能にします。
-
一般的なMLOpsまたはCI/CDパイプラインを自動化します。
-
イベントまたはアクションによってトリガーされるバッチまたはワークロードの実行。
-
バッチ、ミニ・バッチまたは分散バッチ・ジョブ推論。
-
バッチ・ワークロードを処理します。
-
独自のコンテナを持ち込みます。
通常、MLおよびデータ・サイエンス・プロジェクトは、次のような一連のステップです:
-
アクセス
-
探索
-
準備
-
モデル
-
トレーニング
-
検証
-
デプロイ
-
テスト
ステップが完了したら、ジョブを使用してデータ探索、モデルのトレーニング、デプロイおよびテストのプロセスを自動化できます。データ準備やモデル学習における1回の変更、ハイパーパラメータのチューニングによる実験などをジョブとして実行し、個別にテストできます。
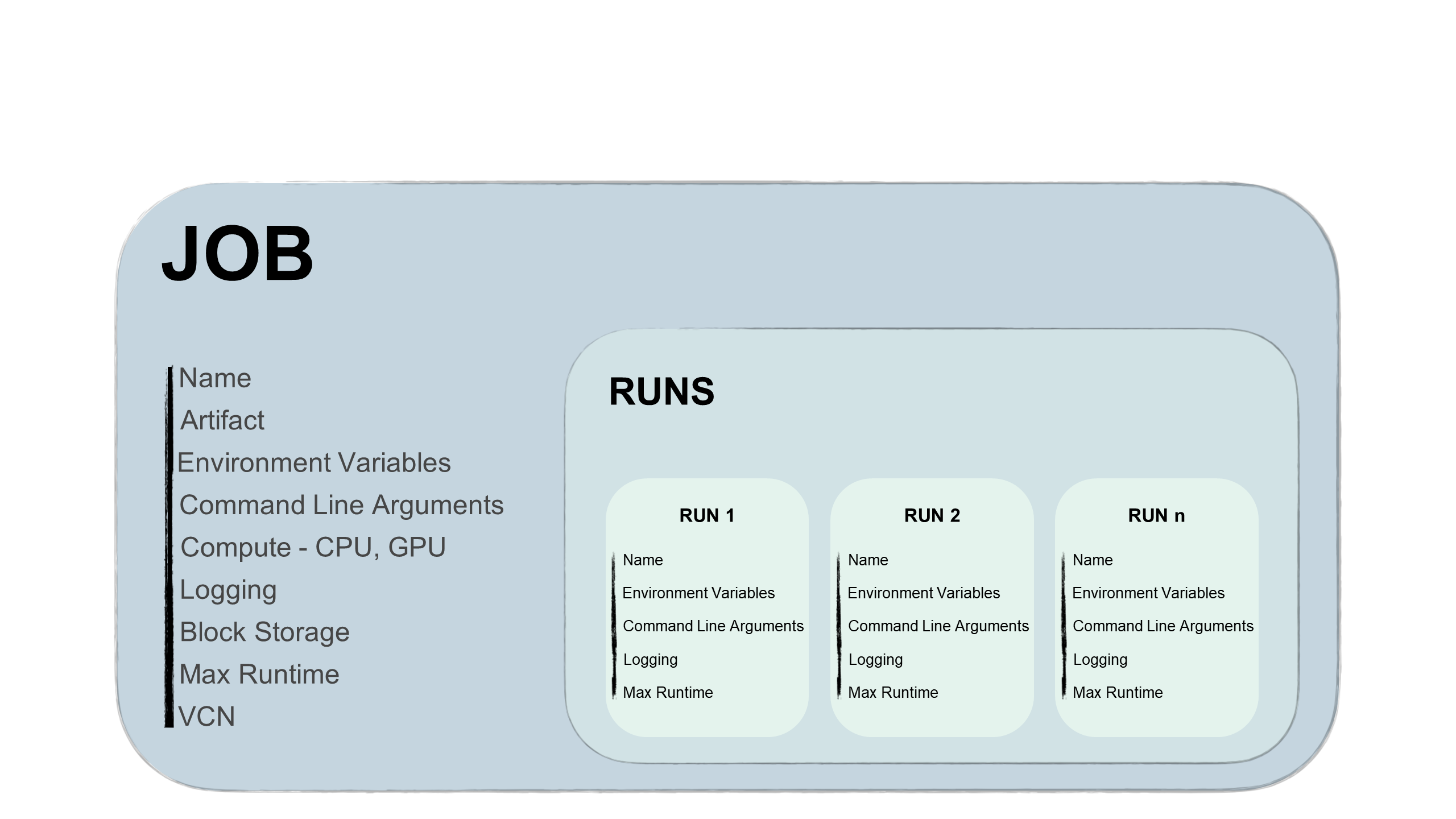
ジョブは、ジョブとジョブ実行の2つの部分で構成されます:
- ジョブ
-
ジョブは、タスクを説明するテンプレートです。これには、ジョブ・アーティファクトなどの要素が含まれており、ジョブにアップロードした後に変更することはできません。また、ジョブには、ジョブが実行されるコンピュート・シェイプ、ロギング・オプション、ブロック・ストレージおよびその他のオプションに関する情報が含まれます。環境変数やCLI引数をジョブに追加し、今後のすべてのジョブ実行で一意または類似にすることができます。これらの変数および引数をジョブ実行でオーバーライドできます。
ジョブ内およびジョブ実行間でコンピュート・シェイプを編集できます。たとえば、より強力なシェイプでジョブ実行を実行する場合、ジョブ・コンピュート・シェイプを編集してから、新しいジョブ実行を開始できます。
ヒント
シェイプを編集するために、ジョブ実行が完了するのを待つ必要はありません。
- ジョブ実行
-
ジョブ実行は実際のジョブ・プロセッサです。ジョブの実行ごとに、いくつかのジョブ構成オプションをオーバーライドできます。最も重要なのは、環境変数とCLI引数をオーバーライドできることです。同じジョブで、異なるパラメータを使用して順次または同時に開始する複数のジョブ実行を持つことができます。たとえば、異なるハイパーパラメータを指定して、同じモデルのトレーニング・プロセスがどのように実行されるかを試すことができます。
ジョブ・ライフサイクル
ジョブ・ライフサイクルの各ステージでは、通知の送信、サード・パーティ機能のトリガー、または別のジョブ実行のトリガーに使用できるイベントがトリガーされます。
- ジョブの作成
-
ジョブの作成は、ジョブ・アーティファクト・ファイルの指定を含むジョブ構成を作成することです。ジョブ・アーティファクトにはジョブの実行可能コードが含まれます。このアーティファクトは、Python、Bash/シェル、またはPythonまたはJavaで記述されたプロジェクト全体を含むzipまたは圧縮tarファイルです。
また、ジョブ・アーティファクトを実行するコンピュート・シェイプと、ブロック・ストレージおよびネットワーキングを指定します。様々なCPUシェイプとGPUシェイプ、および最大1TBのブロック・ストレージを選択できる柔軟性があります。ロギング・オプションでは、ジョブ実行ごとに自動ロギング作成を設定できます。
ストレージマウントは次のように使用できます。
- 他の場所からアクセスできるモデル・トレーニング中にログを格納します。
- モデル・トレーニング中にチェックポイントを格納して、最後のチェックポイントからモデルのトレーニングを続行し、最初からトレーニングを開始しないようにします。
- 共通ファイル・システム・マウントからのデータの格納および読取りを行うため、ジョブを実行しているマシンにデータをコピーする必要はありません。
- ジョブ実行の開始
-
これはジョブ・プロセッサです。ジョブ実行の開始では、一部の構成済パラメータを変更してユース・ケースを変更できます。
ジョブ実行では、いくつかのライフサイクル操作が使用されます。ジョブ実行では、データ・サイエンス・サービスはインフラストラクチャのプロビジョニング、ジョブ・アーティファクトの実行、ジョブ・アーティファクトの実行の完了時のインフラストラクチャのプロビジョニングの解除を処理します。
1つのジョブは、順次または同時に実行できる多くのジョブ実行を持つことができます。ジョブ実行の最大実行時間を構成できます。構成された最大実行時間を超えてジョブ実行が進行中の場合、データ・サイエンス・サービスはジョブ実行を自動的に取り消します。ランナウェイ・ジョブ実行を回避するために、すべてのジョブ実行に最大実行時間を構成することをお薦めします。
ノート
ジョブ実行の最大実行時間の上限は30日です。この値が構成されていない場合でも、30日の制限が適用されます。
- モニタリング
-
ロギング・サービスでロギングを有効化し、ジョブの実行中にプロセスをモニターできます。メッセージは、ジョブ実行およびジョブ・アーティファクト・ファイルについて記録されます。
モニタリングは、潜在的なエラーをデバッグし、使用されるリソースをモニターするのに役立ちます。
- 終了
-
ジョブ実行はコード・プロセス終了で終了します。ジョブ実行の最終ライフサイクルをトリガーします。これはインフラストラクチャのプロビジョニング解除です。ジョブ実行を取り消す場合も、インフラストラクチャは破棄されます。
クラウド・リソースへのジョブ・アクセス
ジョブは、許可するポリシーがあるかぎり、テナンシ内のすべてのOCIリソースにアクセスできます。ADWまたはオブジェクト・ストレージ内のデータに対してジョブを実行できます。また、ボールトを使用して、サードパーティのリソースに対して認証するための安全な方法を提供することもできます。適切なVCNを構成している場合、ジョブは外部ソースにアクセスできます。
ジョブ実行アクセス
ジョブ実行はOCI SDKおよびAPIをサポートします。考えられるすべての外部サードパーティ・サービスからジョブを実行することができます。次に例を示します:
- クライアント・マシン、MLOpsまたはCI/CDパイプライン。
- GitHubまたはBitbucket CI/CDパイプライン。
- Oracle AIサービスまたはサードパーティ。
- イベント・サービス。
OCIコンソールでジョブを作成してジョブ実行を開始できます。次を使用してジョブを作成および実行することもできます:
-
Python
-
Java
-
JavaScript
-
TypeScript
-
Go
-
Ruby
-
OCI CLI
-
Terraform