Data Science-Jobausführungen planen
In diesem Tutorial planen Sie mit Data Integration Jobläufe für Ihre Data Science-Jobs.
Zu den wichtigsten Aufgaben gehören:
- Erstellen Sie einen Job mit einem Data Science-Jobartefakt.
- Richten Sie eine REST-Aufgabe ein, um einen Job mit denselben Details wie der mit dem Artefakt erstellte Job zu erstellen.
- Richten Sie einen Zeitplan ein, und weisen Sie ihn der REST-Aufgabe zu.
- Lassen Sie den Taskplaner die Data Science-Jobs erstellen.
Bevor Sie beginnen
Um dieses Tutorial erfolgreich ausführen zu können, benötigen Sie Folgendes:
-
Ein kostenpflichtiger Oracle Cloud Infrastructure-Account oder ein neuer Account mit Oracle Cloud-Aktionen (siehe Kostenlose Oracle Cloud-Promotions anfordern und verwalten).
- Einen MacOS-, Linux- oder Windows-Rechner.
1. Vorbereiten
Erstellen Sie dynamische Gruppen, Policys, ein Compartment und ein Data Science-Projekt für Ihr Tutorial, und richten Sie sie ein.
Führen Sie das Tutorial Data Science-Mandanten manuell konfigurieren mit den folgenden Details aus:
Wenn Sie Data Science-Mandanten manuell konfigurieren bereits ausgeführt haben, lesen Sie die nächsten Schritte, und integrieren Sie die Policys, die für dieses Tutorial gelten.
Lassen Sie zu, dass der Data Integration-Service Workspaces erstellt.
In diesem Schritt fügen Sie der Gruppe data-science-dynamic-group Data Integration-Workspaces hinzu. Mit data-science-dynamic-group-policy können alle Mitglieder dieser dynamischen Gruppe die data-science-family verwalten. Auf diese Weise können die Workspace-Ressourcen wie Aufgabenpläne Ihre Data Science-Jobs erstellen.
2. Joblauf einrichten
Erstellen Sie ein hello world-Python-Jobartefakt für Ihren Job und die Jobläufe:
Führen Sie hello_world_job aus:
Wenn Sie einen Job erstellen, legen Sie die Infrastruktur und die Artefakte für den Job fest. Anschließend erstellen Sie einen Joblauf, der die Infrastruktur bereitstellt, das Jobartefakt ausführt und nach Beendigung des Jobs die verwendeten Ressourcen entfernt und zerstört.
-
Wählen Sie auf der Seite
hello_world_jobdie Option Joblauf starten aus. -
Wählen Sie das Compartment
data-science-workaus. -
Namen des Joblaufs:
hello_world_job_run_test. - überspringen Sie die Abschnitte Loggingkonfigurationen außer Kraft setzen und Jobkonfiguration außer Kraft setzen.
- Wählen Sie Start.
- Wählen Sie im Trail, in dem die aktuelle Seite angezeigt wird, also die Seite mit den Joblaufdetails, die Option Jobläufe aus, um zurückzugehen und die Liste der Jobläufe abzurufen.
- Warten Sie für hello_world_job_run_test, bis der Status von Angenommen in In Bearbeitung und schließlich in Erfolgreich geändert wird, bevor Sie mit dem nächsten Schritt fortfahren.
Um hello_world_job für die Planung verwenden zu können, müssen Sie einige Informationen zum Job vorbereiten:
3. Aufgabe einrichten
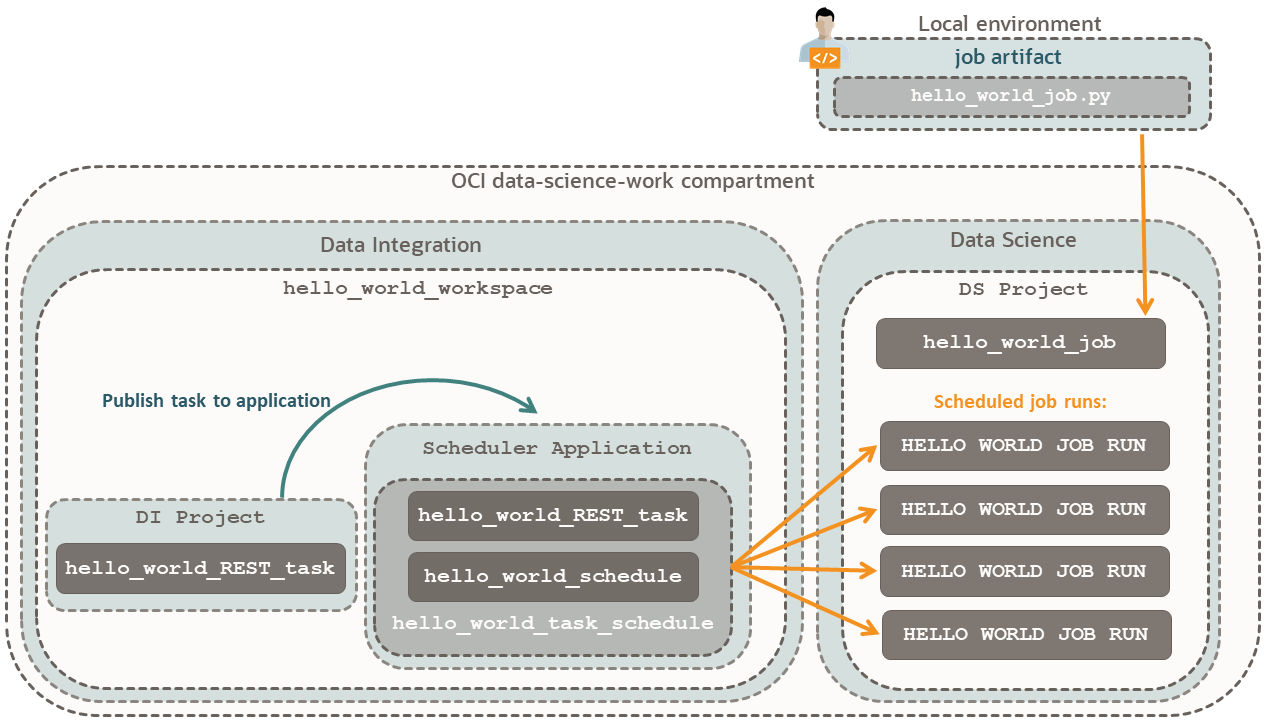
Eine visuelle Beziehung der Komponenten finden Sie im Scheduler-Diagramm.
Erstellen Sie einen Workspace, um ein Projekt mit einer Aufgabe zu hosten, die Jobläufe erstellt.
Dieser Workspace verwendet datascience-vcn, und der von Ihnen erstellte Data Science-Job verwendet die Option Standardmäßiges Networking von Data Science. Da Sie dem Data Integration-Service Zugriff auf alle Ressourcen im Compartment data-science-work erteilt haben, ist es egal, ob die VCNs unterschiedlich sind. Data Integration verfügt über einen Scheduler in datascience-vcn, der Jobläufe im VCN unter Standardmäßiges Networking erstellt.
Aktualisieren Sie in hello_world_workspace den systemgenerierten Projektnamen.
Sie ändern den Projektnamen, damit ersichtlich ist, dass es sich bei diesem Projekt um ein Data Integration-Projekt und kein Data Science-Projekt handelt.
Erstellen Sie eine Aufgabe, und definieren Sie die REST-API-Parameter zum Erstellen eines Joblaufs.
Wenn im Workspace angezeigt wird, dass die REST-Task erfolgreich erstellt wurde, klicken Sie auf Speichern und schließen.
Im Anforderungstext der REST-Aufgabe können Sie den zum Erstellen eines Joblaufs erforderlichen Parametern Werte zuweisen. Sie verwenden dieselben Werte wie bei
hello_world_job, die Sie im Abschnitt Job erstellen dieses Tutorials in Data Science erstellt haben.Referenzen:
Erstellen Sie eine Scheduler-Anwendung, die Ihre REST-Aufgabe nach einem Zeitplan ausführt.
-
Wählen Sie im Arbeitsbereich
hello_world_workspaceim Bereich Schnellaktionen die Option Anwendung erstellen aus. -
Name der Anwendung:
Scheduler Application. - Wählen Sie Erstellen.
Fügen Sie hello_world_REST_task zu Scheduler Application hinzu:
-
Navigieren Sie im Trail, der die aktuelle Seite anzeigt, zum Workspace
hello_world_workspace, und wählen Sie den Link Projekte aus. - Wählen Sie DI-Projekt aus.
- Wählen Sie Aufgaben.
-
Wählen Sie in der Liste der Aufgaben das Menü Aktionen (drei Punkte) für
hello_world_REST_taskaus, und wählen Sie In Anwendung veröffentlichen aus. - Wählen Sie unter Anwendungsname die Option Scheduler-Anwendung aus.
- Wählen Sie veröffentlichen aus.
Bevor Sie hello_world_REST_task planen, testen Sie die Aufgabe, indem Sie sie manuell ausführen:
Stellen Sie sicher, dass die Data Science-Jobläufe die Aufgabe enthalten, die Sie von Data Integration ausgeführt haben.
4. Aufgabe planen und ausführen
Erstellen Sie einen Zeitplan, um die veröffentlichte Aufgabe hello_world_REST_task auszuführen.
- In diesem Schritt richten Sie einen Zeitplan in der Datei
Scheduler Application.ein. Im nächsten Schritt verknüpfen Sie den Zeitplan mithello_world_REST_task.
Referenz: Veröffentlichte Aufgaben planen
Weisen Sie hello_world_schedule der veröffentlichten Aufgabe hello_world_REST_task zu:
Stellen Sie sicher, dass die Data Science-Jobläufe die geplante Aufgabe aus Data Integration enthalten.
Wenn mindestens ein Joblauf abgeschlossen ist, sind Sie mit diesem Tutorial fertig. Sie können den Scheduler jetzt deaktivieren und neue Jobläufe stoppen.
-
Klicken Sie in
hello_world_workspaceauf Anwendungen,Scheduler Application. - Wählen Sie im linken Navigationsbereich die Option Aufgaben.
-
Wählen Sie
hello_world_REST_taskaus. -
Klicken Sie in der Liste der Aufgabenpläne auf
hello_world_REST_task_schedule. - Wählen Sie Deaktivieren.
- Wählen Sie im Bestätigungsdialogfeld Deaktivieren aus.
- Wenn Sie mehrere Aufgabenpläne für dieses Tutorial erstellt haben, deaktivieren Sie alle.
Weitere Schritte
Sie haben erfolgreich Data Science-Jobläufe geplant.
Weitere Informationen zu Data Science-Jobs finden Sie in den folgenden Abschnitten in der Data Science-Dokumentation:
Weitere Informationen zu Data Science finden Sie in den Data Science-Tutorials und den Data Science-Schulungsvideos.