Batch Inference for Jobs
Learn how to use the various types of batch inference uses with jobs.
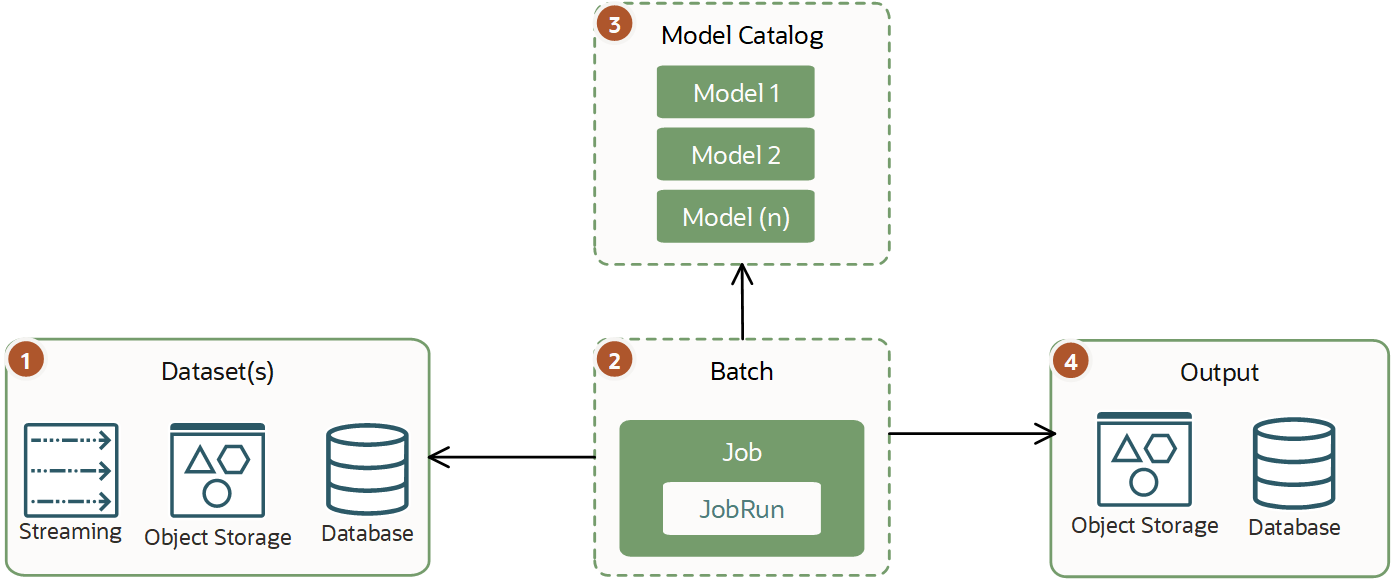
Traditional batch inference is an asynchronous process that's executing predictions based on existing models and observations, and then stores the output. This batch inference is a single virtual machine job that you can run with Data Science jobs.
Typically, a workload varies, but it's bigger than a mini batch inference and could require several hours or days to finish. This type of workload doesn't require producing near or real-time results. It can have extensive requirements on the CPU or GPU and memory required to run.
For best performance, use the AI and ML model directly rather than calling it over HTTP or another network. Using the model directly is especially important when you require heavy processing with large datasets. For example, processing images.
Mini Batch Inference
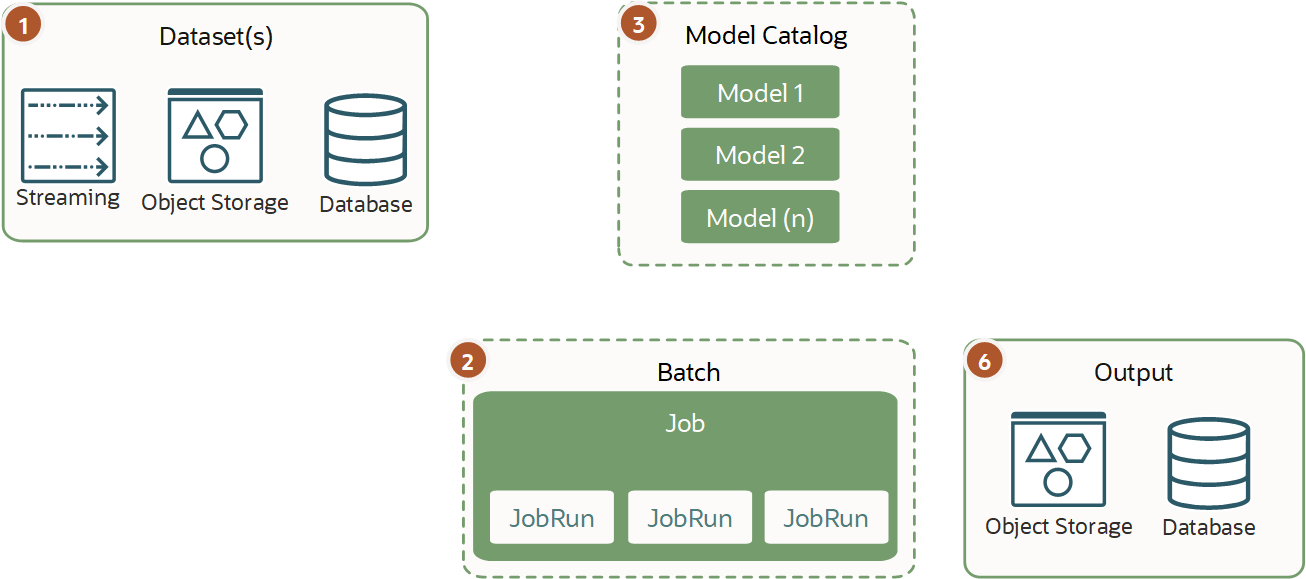
Mini batch inference is similar to batch inference with the difference that you can split tasks into small batches using several jobs or one job that runs several small tasks simultaneously.
Because the tasks are small and the mini batches are run regularly, they usually run only for several minutes. This type of workload is run regularly using schedulers or triggers to work on small groups of data. Mini batching helps you to incrementally load and process small parts of data or inference.
You can run mini batches against a model from the model catalog when the best performance is required or against the deployed model because usually the workloads and the data input aren't heavy.
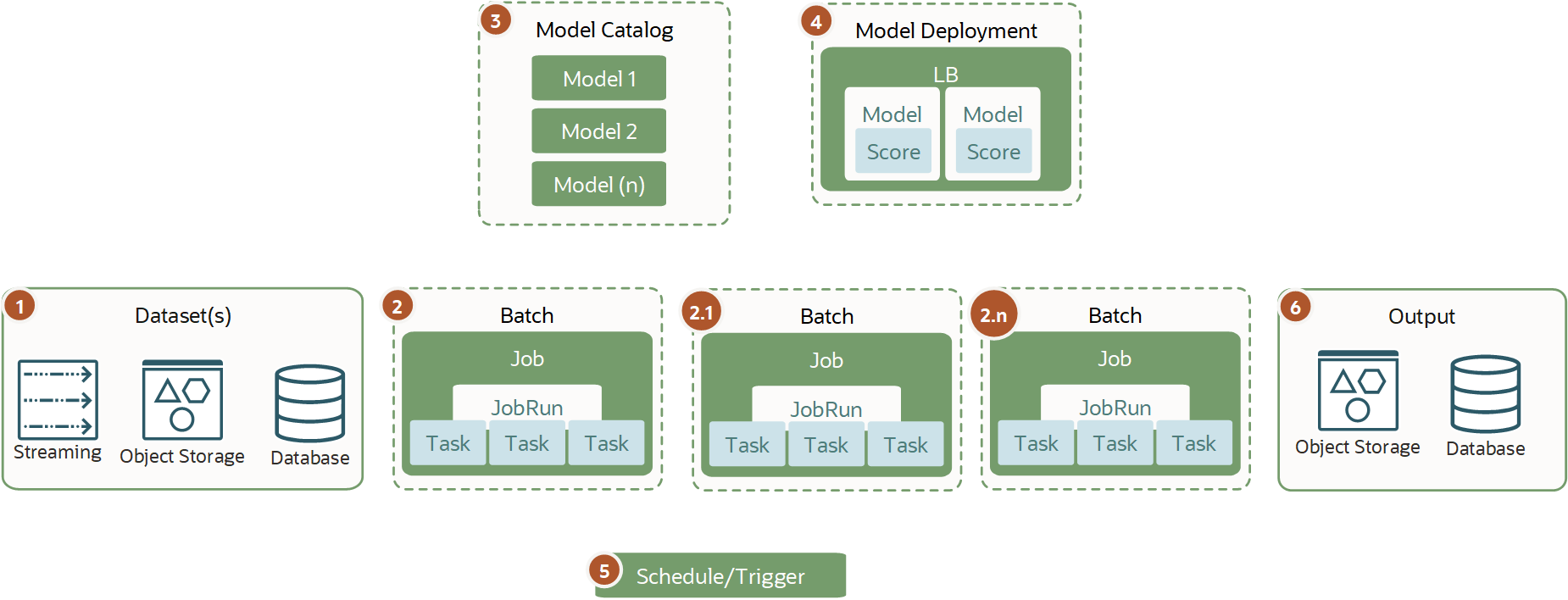
Distributed Batch Inference
You use distributed batch inference for heavy duty jobs.
Don't confuse distributed batch inference with distributed model training because they're different. Also, it's not a model deployment type of inference because typically you want to provision and use the infrastructure only during the time of batch inference, and automatically destroy it when complete.
Distributed batch inference is required on a large dataset and heavy inference that can't be processed in a timely matter on a single VM or BM and require horizontal scaling. You can have a single or several job configurations running (1+n) job runs on various types of infrastructure and split the dataset. This type of workload provides the best performance when they work against the AI and ML model directly from the model catalog using the infrastructure memory and CPU or GPU to the maximum using jobs.
Compare Batch Inference Workloads
A high-level comparison between the different types of workloads and the corresponding batch inference types:
|
Batch Inference |
Mini Batch Inference |
Distributed Batch Inference |
|
|---|---|---|---|
|
Infrastructure |
Large |
Light to medium |
Very large |
|
VM |
Single |
Single or many (at a small scale) |
Many |
|
Provisioning Speed - Required |
Medium |
Fast |
Average to slow |
|
Scheduler - Required |
Yes |
Yes |
Use case dependent |
|
Trigger - Required |
Yes |
Yes |
No |
|
Workloads |
Large |
Light |
Large or heavy |
|
Datasets Size |
Large |
Small |
Extremely large or autoscaling |
|
Batch Process Time (estimate though could differ depending on use case) |
Medium to very long (from two digits minutes long process to days or hours) |
Short to near real-time |
Medium to very long (from few hours up to days) |
|
Model Deployment |
Not required |
Yes, but not required |
Not required |
|
Endpoints |
No |
No |
No |