データ・フローとデータ・サイエンスの統合
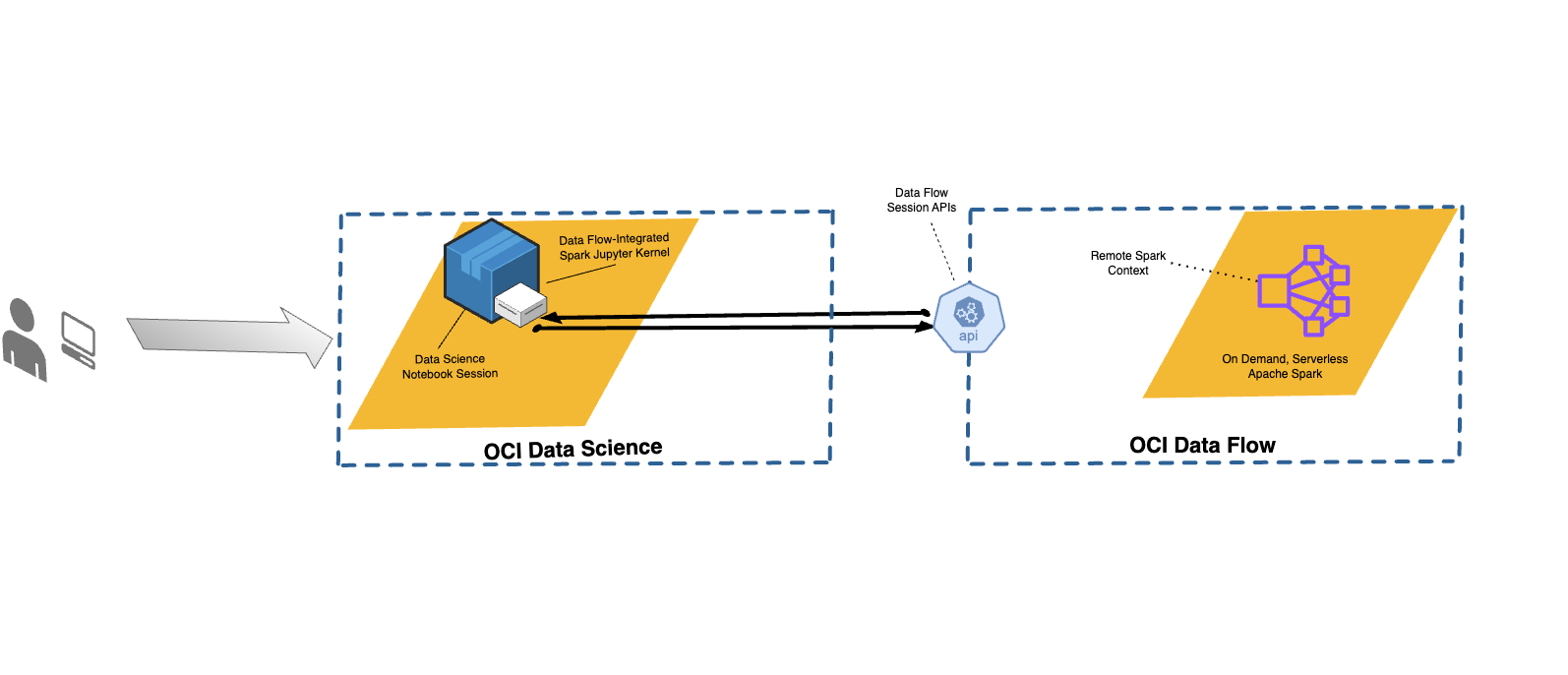
データ・フローを使用すると、データ・フローに対して対話形式でアプリケーションを実行するよう、データ・サイエンス・ノートブックを構成できます。
データ・フローでは、完全管理型のJupyter Notebookを使用して、データ・サイエンティストやデータ・エンジニアが、データ・エンジニアリング・アプリケーションおよびデータ・サイエンス・アプリケーションの作成、ビジュアル化、コラボレーション、デバッグを実行できるようにしています。これらのアプリケーションは、Python、ScalaおよびPySparkで記述できます。また、データ・サイエンス・ノートブック・セッションをデータ・フローに接続して、アプリケーションを実行することも可能です。データ・フロー・カーネルおよびアプリケーションは、Oracle Cloud Infrastructureデータ・フローで実行されます。
Apache Sparkは、データを大規模に処理するよう設計された分散コンピューティング・システムです。大規模なSQL、バッチ、ストリーム処理および機械学習のタスクがサポートされています。Spark SQLでは、データベースのようなサポートが行われます。構造化データを問い合せるには、Spark SQLを使用します。ANSI標準のSQL実装です。
データ・フロー・セッションでは、データ・フロー・クラスタの自動スケーリング機能がサポートされています。詳細は、データ・フローのドキュメントの「自動スケーリング」を参照してください。
データ・フロー・セッションでは、カスタマイズ可能なSparkランタイム環境として、conda環境の使用がサポートされています。
- 制限事項
-
-
データ・フロー・セッションの存続期間は、最大7日間または10,080分(maxDurationInMinutes)です。
- データ・フロー・セッションのデフォルトのアイドル・タイムアウト値(idleTimeoutInMinutes)は480分(8時間)です。別の値を構成できます。
- データ・フロー・セッションを使用できるのは、データ・サイエンス・ノートブック・セッションを介した場合のみです。
- サポートされているのは、Sparkバージョン3.5.0および3.2.1のみです。
-
データ・フロー・スタジオでのデータ・サイエンスの使用に関するチュートリアル・ビデオをご覧ください。また、データ・サイエンスとデータ・フローの統合の詳細は、Oracle Accelerated Data Science SDKのドキュメントも参照してください。
Conda環境のインストール
データ・フロー・マジックとデータ・フローを使用するには、次のステップを実行します。
データ・フローおよびデータ・サイエンスの使用
データ・フローとデータ・サイエンスを組み合せて使用してアプリケーションを実行するには、次のステップを実行します。
-
データ・フローでノートブックを使用するようポリシーが設定されていることを確認します。
-
データ・サイエンス・ポリシーが正しく設定されていることを確認します。
- サポートされているすべてのコマンドのリストを表示するには、
%helpコマンドを使用します。 - 次のステップのコマンドは、Spark 3.5.0とSpark 3.2.1の両方に適用されます。例では、Spark 3.5.0が使用されています。使用するSparkのバージョンに従って、
sparkVersionの値を設定します。
Conda環境でのデータ・フローSpark環境のカスタマイズ
公開されているconda環境をランタイム環境として使用できます。
データ・フローでのspark-nlpの実行
Spark-nlpをインストールし、データ・フローで実行するには、次のステップに従います。
Conda環境を使用したデータ・フローSpark環境のカスタマイズのステップ1および2を完了している必要があります。spark-nlpライブラリは、pyspark32_p38_cpu_v2 conda環境に事前にインストールされています。
例
次に、データFlowMagicの使用例を示します。
PySpark
scはSparkを表し、%%spark magicコマンドを使用すると利用可能になります。次のセルは、データFlowMagicセルでscを使用する方法を大まかに表した例です。セルでは、番号のリストからRDD、numbersを作成する.parallelize()メソッドがコールされています。RDDに関する情報が出力されます。.toDebugString()メソッドにより、RDDの説明が返されます。%%spark
print(sc.version)
numbers = sc.parallelize([4, 3, 2, 1])
print(f"First element of numbers is {numbers.first()}")
print(f"The RDD, numbers, has the following description\n{numbers.toDebugString()}")Spark SQL
-c SQLオプションを使用すると、セルでSpark SQLコマンドを実行できます。この項では、citi bikeデータセットを使用します。次のセルでは、データセットをSparkデータフレームに読み取り、表として保存します。この例は、Spark SQLの表示に使用されます。
%%spark
df_bike_trips = spark.read.csv("oci://dmcherka-dev@ociodscdev/201306-citibike-tripdata.csv", header=False, inferSchema=True)
df_bike_trips.show()
df_bike_trips.createOrReplaceTempView("bike_trips")次の例では、-c sqlオプションを使用して、セルのコンテンツがSparkSQLであることをデータFlowMagicに通知します。-o <variable>オプションは、Spark SQL操作の結果を取得し、定義された変数に格納します。この場合、
df_bike_tripsは、ノートブックで使用できるPandasデータフレームです。%%spark -c sql -o df_bike_trips
SELECT _c0 AS Duration, _c4 AS Start_Station, _c8 AS End_Station, _c11 AS Bike_ID FROM bike_trips;df_bike_trips.head()sqlContextを使用して表を問い合せることができます:%%spark
df_bike_trips_2 = sqlContext.sql("SELECT * FROM bike_trips")
df_bike_trips_2.show()%%spark -c sql
SHOW TABLES自動ビジュアライゼーション・ウィジェット
データFlowMagicには、パンダ・データフレームをビジュアル化できるautovizwidgetが付属しています。display_dataframe()関数では、Pandasデータフレームがパラメータとして取得され、ノートブックに対話型のGUIが生成されます。このタブには、データの可視化が表、円グラフ、散布図、棒グラフなど様々な形式で表示されます。
df_peopleデータフレームを使用してdisplay_dataframe()がコールされます:from autovizwidget.widget.utils import display_dataframe
display_dataframe(df_bike_trips)Matplotlib
データ・サイエンティストが行う一般的なタスクは、データのビジュアル化です。データセットが大きい場合、通常は不可能であるため、ほとんどの場合、データ・フローSparkクラスタからノートブック・セッションにデータをプルすることはお薦めしません。この例では、サーバー側のリソースを使用してプロットを生成し、それをノートブックに含める方法を証明します。
%matplot plt magicコマンドを使用すると、サーバー側でレンダリングされていても、ノートブックのプロットを表示できます:%%spark
import matplotlib.pyplot as plt
df_bike_trips.groupby("_c4").count().toPandas().plot.bar(x="_c4", y="count")
%matplot plt詳細な例
データ・フローおよびデータ・サイエンス・サンプルに関するその他の例は、GitHubを参照してください。