Despliegues de modelo
Descubra cómo trabajar con los despliegues de modelo de Data Science.
Los despliegue de modelos son un recurso gestionado en el servicio OCI Data Science que se utiliza para desplegar modelos de aprendizaje automático como puntos finales HTTP en OCI. El despliegue de modelos de aprendizaje automático como aplicaciones web (puntos finales de API de HTTP) que sirven predicciones en tiempo real es la forma más común de producción de modelos. Los puntos finales HTTP son flexibles y pueden servir solicitudes de predicciones de modelos.
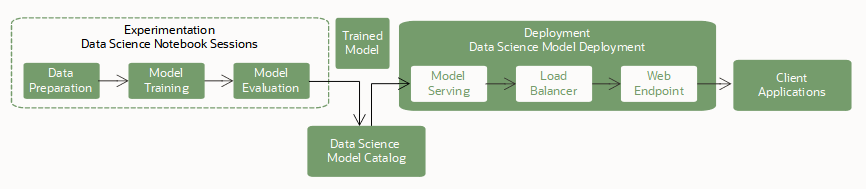
Entrenamiento
El entrenamiento de un modelo es el primer paso para desplegar un modelo. Utilice sesiones de bloc de notas y trabajos para entrenar modelos de código abierto y de Oracle AutoML.
Guardado y almacenamiento
A continuación, almacene el modelo entrenado en el catálogo de modelos. Tiene las siguientes opciones para guardar un modelo en el catálogo de modelos:
- El SDK de ADS proporciona una interfaz para especificar un modelo de código abierto, preparar su artefacto de modelo y guardar ese artefacto en el catálogo de modelos.
-
Puede utilizar la consola, los SDK y las CLI de OCI para guardar el artefacto del modelo en el catálogo de modelos.
-
Utilice diferentes marcos como scikit-learn, TensorFlow o Keras.
El despliegue del modelo requiere que especifique un entorno conda de inferencia en el archivo de artefacto de modelo runtime.yaml. Este entorno conda de referencia contiene todas las dependencias del modelo y se instala en el contenedor del servidor de modelos. Puede especificar uno de los entornos conda de Data Science o un entorno publicado que haya creado.
Despliegue de modelo
Una vez guardado un modelo en el catálogo de modelos, estará disponible para su despliegue como recurso de despliegue de modelo. El servicio soporta modelos que se ejecutan en un entorno de tiempo de ejecución de Python, y sus dependencias se pueden empaquetar en un entorno conda.
Puede desplegar y llamar a un modelo mediante la consola de OCI, los SDK de OCI, la CLI de OCI y el SDK de ADS en sesiones de bloc de notas.
Los despliegues de modelos se basan en estos componentes clave para desplegar un modelo como punto final HTTP:
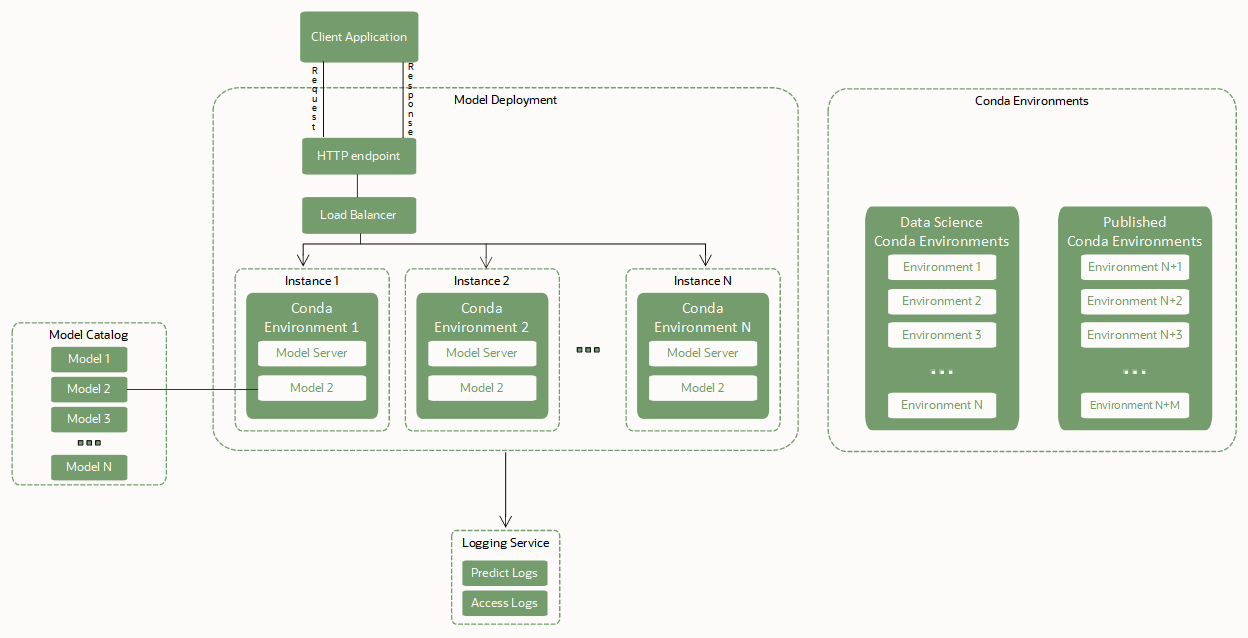
- Load Balancer.
-
Cuando se crea un despliegue de modelo, se debe configurar un equilibrador de carga. Un equilibrador de carga proporciona una forma automatizada de distribuir el tráfico de un punto de entrada a muchos servidores de modelos que se ejecutan en un pool de máquinas virtuales (VM). El ancho de banda del equilibrador de carga se debe especificar en Mbps y es un valor estático. Puede cambiar el ancho de banda del equilibrador de carga editando el despliegue del modelo.
- Pool de instancias de VM que alojan el servidor de modelos, el entorno conda y el propio modelo.
-
Se realiza una copia del servidor de modelos en cada instancia informática en el pool de máquinas virtuales.
Una copia del entorno conda de inferencia y el artefacto de modelo seleccionado también se copian en cada instancia del pool. Se cargan dos copias del modelo en la memoria para cada OCPU de cada instancia de VM del pool. Por ejemplo, si selecciona una instancia VM.Standard2.4 para ejecutar el servidor de modelos, se cargan en la memoria 4 OCPU x 2 = 8 copias del modelo. Varias copias del modelo ayudan a gestionar solicitudes simultáneas que se realizan al punto final del modelo mediante la distribución de esas solicitudes entre las réplicas del modelo en la memoria de VM. Asegúrese de seleccionar una unidad de VM con un espacio de memoria lo suficientemente grande como para tener en cuenta esas réplicas de modelos en la memoria. Para la mayoría de los modelos de Machine Learning con tamaños en MB o un número bajo de GB, es probable que la memoria no sea un problema.
El equilibrador de carga distribuye las solicitudes realizadas al punto final del modelo entre las instancias del pool. Recomendamos que utilice unidades de VM más pequeñas para alojar el modelo con un mayor número de instancias en lugar de seleccionar menos VM aunque de mayor tamaño.
- Artefactos de modelo en el catálogo de modelos.
-
El despliegue del modelo requiere un artefacto de modelo que esté almacenado en el catálogo de modelos y que el modelo esté en estado activo. El despliegue del modelo expone la función
predict()definida en el archivo score.py del artefacto de modelo. - Entorno Conda con dependencias de tiempo de ejecución de modelo.
-
Un entorno conda encapsula todas las dependencias Python de terceros (como Numpy, Dask o XGBoost) que requiere un modelo. Los entornos conda de Python soportan las versiones
3.7,3.8,3.9,3.10y3.11de Python. La versión de Python que especifique conINFERENCE_PYTHON_VERSIONdebe coincidir con la versión utilizada al crear el paquete conda.El despliegue del modelo extrae una copia del entorno conda de inferencia definido en el archivo runtime.yaml del artefacto de modelo para desplegar el modelo y sus dependencias. La información relevante sobre el entorno de despliegue de modelo se encuentra en el parámetro
MODEL_DEPLOYMENTdel archivoruntime.yaml. Los parámetrosMODEL_DEPLOYMENTse capturan automáticamente cuando se guarda un modelo mediante ADS en una sesión de bloc de notas. Para guardar un modelo en el catálogo y desplegarlo mediante el SDK, la CLI o la consola de OCI, debe proporcionar un archivoruntime.yamlcomo parte de un artefacto de modelo que incluya esos parámetros.Nota
Para todos los artefactos de modelo guardados en el catálogo de modelos sin un archivo
runtime.yamlo cuando falte el parámetroMODEL_DEPLOYMENTen el archivoruntime.yaml, se instala un entorno conda por defecto en el servidor de modelos y se utiliza para cargar un modelo. El entorno conda por defecto que se utiliza es General Machine Learning con Python versión 3.8.Utilice estos entornos conda:
- entornos conda de Data Science
-
Puede consultar una lista de los entornos conda en Visualización de entornos conda.
En el siguiente ejemplo, el archivo
runtime.yamlindica al despliegue del modelo que recupere el entorno conda publicado de la ruta de Object Storage definida porINFERENCE_ENV_PATHen ONNX 1.10 para CPU en Python 3.7.MODEL_ARTIFACT_VERSION: '3.0' MODEL_DEPLOYMENT: INFERENCE_CONDA_ENV: INFERENCE_ENV_SLUG: envslug INFERENCE_ENV_TYPE: data_science INFERENCE_ENV_PATH: oci://service-conda-packs@id19sfcrra6z/service_pack/cpu/ONNX 1.10 for CPU on Python 3.7/1.0/onnx110_p37_cpu_v1 INFERENCE_PYTHON_VERSION: '3.7' - Sus entornos conda publicados
-
Puede crear y publicar entornos conda para utilizarlos en despliegues de modelo.
En el siguiente ejemplo, el archivo
runtime.yamlindica al despliegue de modelo que recupere el entorno conda publicado de la ruta de Object Storage definida porINFERENCE_ENV_PATH. A continuación, lo instala en todas las instancias del pool que alojan el servidor de modelos y el propio modelo.MODEL_ARTIFACT_VERSION: '3.0' MODEL_DEPLOYMENT: INFERENCE_CONDA_ENV: INFERENCE_ENV_SLUG: envslug INFERENCE_ENV_TYPE: published INFERENCE_ENV_PATH: oci://<bucket-name>@I/<prefix>/<env> INFERENCE_PYTHON_VERSION: '3.7'
Para todos los artefactos de modelo guardados en el catálogo sin un archivo
runtime.yaml, los despliegues de modelo también utilizan el entorno conda por defecto para el despliegue del modelo. Un despliegue de modelo también puede recuperar un entorno conda de Data Science o un entorno conda que cree o cambie y, a continuación, publique. - Operaciones sin tiempo de inactividad
-
Las operaciones sin tiempo de inactividad para despliegues de modelos significan que el punto final de inferencia del modelo (predicción) puede servir continuamente solicitudes sin interrupción ni inestabilidad.
Los despliegues de modelo soportan una serie de operaciones que se pueden realizar sin tiempo de inactividad. Esta función es fundamental para cualquier aplicación que consuma el punto final del modelo. Puede aplicar operaciones de tiempo de inactividad cero cuando el modelo esté en un estado activo sirviendo solicitudes. Utilice estas operaciones sin tiempo de inactividad para intercambiar el modelo para otro, cambiar la unidad de VM y la configuración de registro, a la vez que se evita el tiempo de inactividad.
- Integración de Logging para capturar logs emitidos desde el despliegue de modelo
-
Puede integrar despliegues de modelo con el servicio Logging. Utilice esta integración opcional para emitar logs desde un modelo y, a continuación, inspeccionar estos logs.
- Contenedor personalizado con dependencias de tiempo de ejecución de modelo
-
Un contenedor personalizado encapsula todas las dependencias de terceros necesarias que un modelo requiere para la inferencia. También incluye un servidor de inferencia preferido, como el servidor de inferencia Triton, el servicio TensorFlow, el servicio de tiempo de ejecución ONNX, etc.
- Inferencia de GPU
-
La inferencia de unidad de procesamiento gráfico se utiliza ampliamente para modelos con un uso intensivo de recursos informáticos, como LLaMa o transformadores preentrenados generativos.
- Salida personalizada
- Puede seleccionar entre red gestionada por servicio o red gestionada por cliente, de forma similar a la salida personalizada con trabajos y blocs de notas.
- Punto final privado
-
Para mejorar la seguridad y el control, puede acceder a despliegues de modelo a través de una red privada (despliegue de modelo privado). Con soporte para puntos finales privados, el tráfico de inferencia permanece de forma segura dentro de la red privada. Para obtener más información, consulte la sección Creación de un punto final privado y Creación de un despliegue de modelo para configurar un despliegue de modelo con un punto final privado.
Detalles de despliegue de modelo
Después de seleccionar un proyecto, se muestra la página de detalles del Proyecto con una lista de sesiones del Notebook y otros recursos, como despliegues de modelo.
Seleccione Despliegues de modelo para ir a la página de detalles de despliegue de modelo para el compartimento seleccionado, donde puede:
-
Cree despliegues de modelo.
-
Seleccione un despliegue de modelo para ver sus detalles y trabajar con él.
-
Utilice el menú para ver detalles, editar, mover un despliegue de modelo o suprimir un despliegue de modelo.
-
OCID: OCID de un recurso. Se muestra una versión abreviada del OCID, aunque puede utilizar Mostrar y ocultar para cambiar la visualización del OCID. Utilice el enlace Copiar para guardar todo el OCID en el portapapeles para pegarlo en otro lugar. Por ejemplo, podría pegarlo en un archivo y guardarlo y, a continuación, utilizarlo en scripts de modelos.
-
Utilizar el filtro Alcance de lista para ver despliegues de modelo asociados al proyecto seleccionado en otro compartimento.
-
Filtre despliegues de modelo por estado utilizando la lista Estado. El valor por defecto es ver todos los tipos de estado.
-
Cuando las etiquetas se aplican a despliegues de modelos, puede filtrar aún más los despliegues de modelos haciendo clic en Agregar o Borrar junto a Filtros de etiquetas.
-
Seleccione otros recursos de Data Science, como modelos, despliegues de modelos y sesiones de Notebook.