Modelos de inteligencia artificial de documentos entrenados previamente
Vision proporciona modelos de IA de documentos preentrenados que le permiten organizar y extraer texto y estructura de documentos comerciales.
Las capacidades AnalyzeDocument y DocumentJob de Vision se están moviendo a un nuevo servicio, Document Understanding. Las siguientes funciones se ven afectadas:
- Detección de tablas
- Clasificación de Documentos
- Extracción de clave-valor de cobro
- OCR de documento
Casos de Uso
Los modelos de IA de documentos previamente entrenados te permiten automatizar las operaciones de back-office y procesar los recibos con mayor precisión.
- Búsqueda inteligente
- Enriquezca los archivos basados en imágenes con metadatos, incluidos el tipo de documento y los campos clave, para facilitar la recuperación.
- Informe de gasto
- Extraiga la información necesaria de los recibos para automatizar los flujos de trabajo de negocio. Por ejemplo, informes de gastos de empleados, cumplimiento de gastos y reembolso.
- Procesamiento de lenguaje natural descendente (NLP)
- Extraiga texto de archivos PDF y organícelo como entrada para NLP, ya sea en tablas o en palabras y líneas.
- Captura de puntos de fidelización
- Automatice los cálculos de puntos de fidelización a partir de las recepciones, en función del número de artículos o el importe total pagado.
Formatos soportados
Vision admite varios formatos de documento.
- JPEG
- PNG
- TIFF
Modelos previamente entrenados
Visión tiene cinco tipos de modelo preentrenado.
Reconocimiento óptico de caracteres (OCR)
Visión puede detectar y reconocer texto en un documento. La clasificación de idioma identifica el idioma de un documento, luego OCR dibuja cuadros delimitadores alrededor del texto impreso o escrito a mano que encuentra en una imagen y digitaliza el texto.
Si tiene un PDF con texto, Vision busca el texto en ese documento y extrae el texto. A continuación, proporciona cuadros delimitadores para el texto identificado. La detección de texto se puede utilizar con modelos de IA de documentos o análisis de imágenes.
Visión proporciona una puntuación de confianza para cada agrupación de texto. La puntuación de confianza es un número decimal. Las puntuaciones más cercanas a 1 indican una mayor confianza en el texto extraído, mientras que las puntuaciones más bajas indican una menor puntuación de confianza. El rango de la puntuación de confianza para cada etiqueta es de 0 a 1.
El soporte de OCR está limitado al inglés. Si sabe que el texto de las imágenes está en inglés, defina el idioma en
Eng.- Extracción de Palabras
- Extracción de línea de texto
- Puntuación de confianza
- Polígonos encuadernados
- Solicitud única
- Solicitud por lotes
- Aunque la clasificación de idiomas identifica varios idiomas, OCR se limita al inglés.
Ejemplo de uso de OCR en Vision.
- Documento de Entrada
-
Entrada de reconocimiento óptico de caracteres

.{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "namespaceName": "", "bucketName": "", "objectName": "", "source": "OBJECT_STORAGE" }, "features": [ { "featureType": "TEXT_DETECTION" }, { "featureType": "LANGUAGE_CLASSIFICATION", "maxResults": 5 } ] } } - Salida:
- Salida de reconocimiento óptico de caracteres
 Respuesta de API:
Respuesta de API: { "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, "detectedLanguages": [ { "languageCode": "ENG", "confidence": 0.9999994 }, { "languageCode": "ARA", "confidence": 4.7619238e-7 }, { "languageCode": "NLD", "confidence": 7.2325456e-8 }, { "languageCode": "CHI_SIM", "confidence": 3.0645523e-8 }, { "languageCode": "ITA", "confidence": 8.6900076e-10 } ], "words": [ { "text": "Example", "confidence": 0.99908227, "boundingPolygon": { "normalizedVertices": [ { "x": 0.0664819944598338, "y": 0.011666666666666667 }, { "x": 0.22160664819944598, "y": 0.011666666666666667 }, { "x": 0.22160664819944598, "y": 0.035 }, { "x": 0.0664819944598338, "y": 0.035 } ] } ... "detectedLanguages": [ { "languageCode": "ENG", "confidence": 0.9999994 } ], ...
Clasificación de Documentos
La clasificación de documentos se puede utilizar para clasificar un documento.
- Factura
- Recepción
- CV
- Formulario de impuestos
- Permiso de conducir
- Pasaporte
- Extracto bancario
- Activar
- Nómina
- Otro
- Clasificar documento
- Puntuación de confianza
- Solicitud única
- Solicitud por lotes
Ejemplo de uso de clasificación de documentos en Visión.
- Documento de Entrada
- Entrada de clasificación de documento
- Salida:
- Respuesta de API:
{ "documentMetadata": { "pageCount": 1, "mimeType": "image/jpeg" }, "pages": [ { "pageNumber": 1, "dimensions": { "width": 361, "height": 600, "unit": "PIXEL" }, "detectedDocumentTypes": [ { "documentType": "RECEIPT", "confidence": 1 }, { "documentType": "TAX_FORM", "confidence": 6.465067e-9 }, { "documentType": "CHECK", "confidence": 6.031838e-9 }, { "documentType": "BANK_STATEMENT", "confidence": 5.413888e-9 }, { "documentType": "PASSPORT", "confidence": 1.5554872e-9 } ], ... detectedDocumentTypes": [ { "documentType": "RECEIPT", "confidence": 1 } ], ...
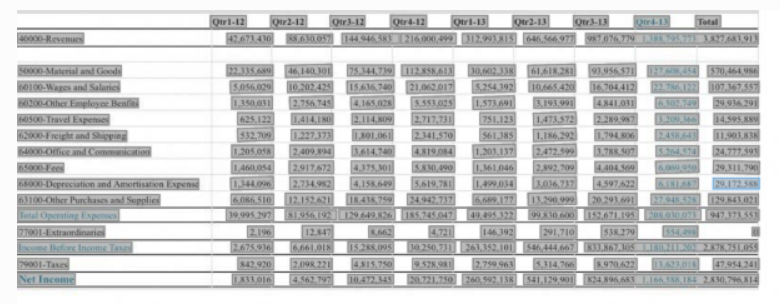
Extracción de tabla
La extracción de tablas se puede utilizar para identificar tablas en un documento y extraer su contenido. Por ejemplo, si un recibo en PDF contiene una tabla que incluye los impuestos y el importe total, Vision identifica la tabla y extrae la estructura de la tabla.
Vision proporciona el número de filas y columnas de la tabla y el contenido de cada celda de la tabla. Cada celda tiene una puntuación de confianza. La puntuación de confianza es un número decimal. Las puntuaciones más cercanas a 1 indican una mayor confianza en el texto extraído, mientras que las puntuaciones más bajas indican una menor puntuación de confianza. El rango de la puntuación de confianza para cada etiqueta es de 0 a 1.
- Extracción de tablas con y sin bordes
- Polígonos encuadernados
- Puntuación de confianza
- Solicitud única
- Solicitud por lotes
- Solo idioma inglés
Ejemplo de uso de extracción de tablas en Vision.
- Documento de Entrada
- Entrada de extracción de tabla

- Salida:
- Salida de extracción de tabla
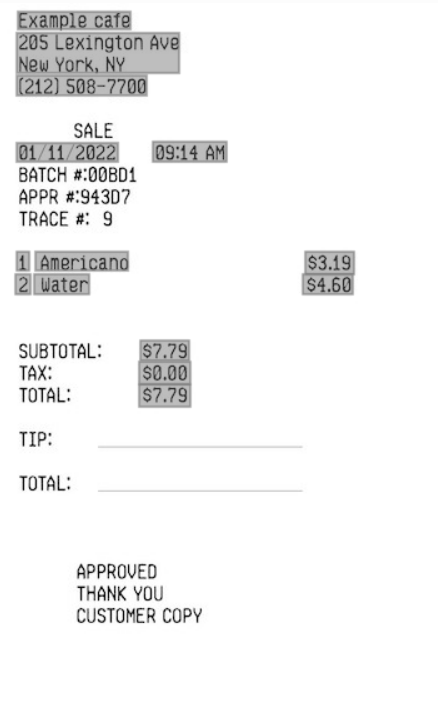
Extracción de valores clave (recibos)
La extracción de valores clave se puede utilizar para identificar valores para claves predefinidas en un cobro. Por ejemplo, si un recibo incluye un nombre de comerciante, una dirección de comerciante o un número de teléfono de comerciante, Vision puede identificar estos valores y devolverlos como un par clave-valor.
- Extraer valores para pares de valores de clave predefinidos
- Polígonos encuadernados
- Solicitud única
- Solicitud por lotes
- Solo soporta recibos en inglés.
- MerchantName
- Nombre del comerciante que emite el recibo.
- MerchantPhoneNumber
- Número de teléfono del comerciante.
- MerchantAddress
- La dirección del comerciante.
- TransactionDate
- Fecha en que se emitió el recibo.
- TransactionTime
- Hora a la que se emitió el recibo.
- Total
- El importe total del recibo, después de que se hayan aplicado todos los cargos e impuestos.
- Subtotal
- Subtotal antes de impuestos.
- Tax
- Cualquier impuesto sobre las ventas.
- Consejo
- La cantidad de propina dada por el comprador.
- ItemName
- Nombre del elemento.
- ItemPrice
- Precio unitario del artículo.
- ItemQuantity
- Número de cada artículo comprado.
- ItemTotalPrice
- Precio total de la línea de ítem.
Ejemplo de uso de extracción de valores clave en Vision.
- Documento de Entrada
- Entrada de extracción de valor clave (recibos)
- Salida:
- Salida de extracción de valor clave (recibos)
PDF de reconocimiento óptico de caracteres (OCR)
OCR PDF genera un archivo PDF apto para búsqueda en Object Storage. Por ejemplo, Vision puede tomar un archivo PDF con texto e imágenes, y devolver un archivo PDF donde puede buscar el texto en el PDF.
- Generar PDF apto para búsqueda
- Solicitud única
- Solicitud por lotes
Ejemplo de uso de PDF de OCR en Vision.
- Entrada
-
Solicitud de API
 de entrada de OCR ODF:
de entrada de OCR ODF:{ "analyzeDocumentDetails": { "compartmentId": "", "document": { "source": "INLINE", "data": "......" }, "features": [ { "featureType": "TEXT_DETECTION", "generateSearchablePdf": true } ] } } - Salida:
- PDF apto para búsqueda.
Uso de modelos de inteligencia artificial de documentos entrenados previamente
Vision proporciona modelos preentrenados para que los clientes extraigan información sobre sus documentos sin necesidad de científicos de datos.
Necesita lo siguiente antes de utilizar un modelo previamente entrenado:
-
Una cuenta de arrendamiento de pago en Oracle Cloud Infrastructure.
-
Familiaridad con Oracle Cloud Infrastructure Object Storage.
Puede llamar a los modelos de IA de documentos previamente entrenados como una solicitud por lotes mediante las API de Rest, SDK o CLI. Puede llamar a los modelos de IA de documentos previamente entrenados como una sola solicitud mediante la consola, las API de Rest, el SDK o la CLI.
Consulte la sección Límites para obtener información sobre lo que se permite en las solicitudes por lotes.