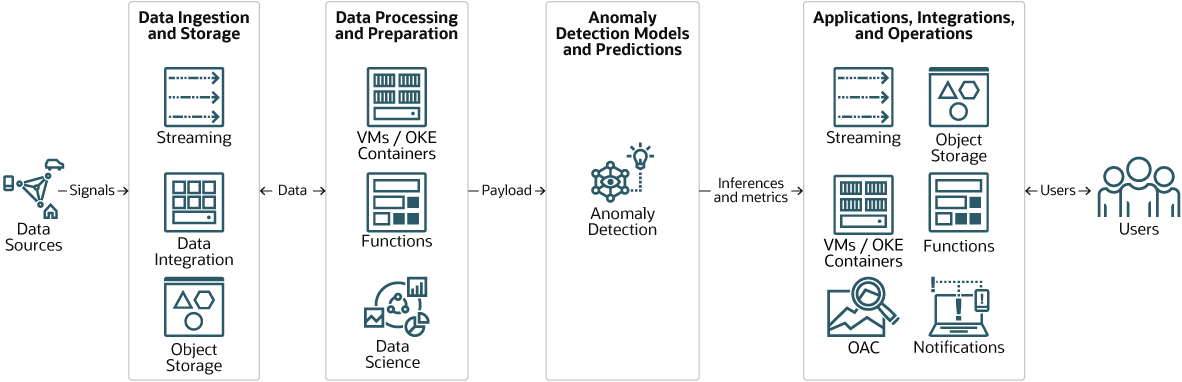
Overview
The Anomaly Detection service is a multi-tenant service that analyzes large volume of multivariate or univariate time series data.
The Anomaly Detection is, accessible over public ReST APIs by authenticated users by using the OCI CLI, SDK or Console. The service is powered by machine learning (ML) and statistical algorithms that understand the complex relationships between different signals in diverse system components. The Anomaly Detection service increases the reliability of businesses by monitoring their critical assets and detecting anomalies early with high precision.
What is Anomaly Detection?
Anomaly detection is the identification of rare items, events, or observations in data that differ significantly from the expectation.
The Anomaly Detection service is designed to help with analyzing large amounts of data and identifying the anomalies at the earliest possible time with maximum accuracy.
The use of the Anomaly Detection service spans across different sectors such as the following:
-
Utility
-
Oil and Gas
-
Transportation
-
Manufacturing
-
Telecommunications
-
Banking
-
Insurance
-
Web Businesses
-
E-commerce
In each of these sectors, you can use the Anomaly Detection service to identify undesirable business incidents and observations, and provide the magnitude of anomaly as the difference between expected and actual values. Anomaly Detection helps you define business-specific alerts and actions. It also helps you to identify anomalies in multivariate and univariate datasets by either taking advantage of interrelationships between signals or by identifying trend in individual signals.
The anomaly detection service uses an innovative statistical method that helps to identify anomalies at the earliest possible time. Also, it productizes univariate and multivariate state estimation methods with sequential probability ratio test techniques, see key terms.
Anomaly Detection Concepts
Learn how Anomaly Detection service to effortlessly organize resources within projects, maintain data assets, train anomaly detection models, and detect anomalies seamlessly.
The Anomaly Detection service provides the infrastructure for maintaining them without the need for in-house Data Science or machine learning specialists.
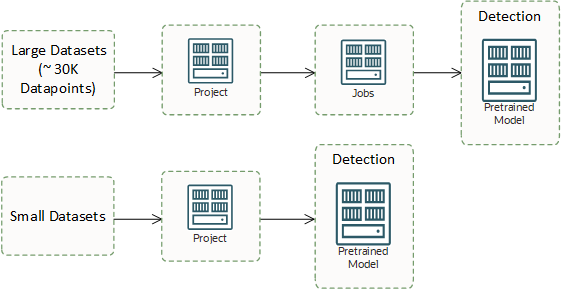
You create a project to be a container for the models that you train, and then detect results using the trained model as follows:
- Projects
-
Projects are collaborative resources for organizing and documenting assets, such as models.
- Data Assets
-
An abstracted data format to contain meta information of the actual data source for model training; it supports multiple types of data sources. The supported data sources are Oracle Object Storage, Oracle Autonomous Transaction Processing, and InfluxDB.
- Models
-
Models define a mathematical representation of a data and business process. They detect anomalies in univariate and multivariate time series data. Models are created as a result of training.
- Private Endpoints
-
Allows you to set up private access to the Anomaly Detection service for data security.
- Jobs
-
Jobs enable creation of detection jobs for large datasets up to 10 million data points (signals * timestamps).
- Training
-
Use a dataset to create a machine learning model using a multivariate or univariate Anomaly Detection service algorithms.
- Detection
-
Identify anomalies in a dataset by using a pretrained multivariate or univariate model.
Key Terms
Review these terms used by the core Machine Learning (ML) engine in the Anomaly Detection service:
|
Technique |
Description |
|---|---|
|
Univariate analysis |
A pattern recognition method that learns one signal in a dataset of time series data. |
|
Multivariate State Estimation Technique (MSET) |
An advanced pattern recognition method that learns the correlation between multiple signals over a large dataset of time series data. It provides accurate estimates for a specific timestamp. |
|
Asynchronous inferencing |
Inferencing performed asynchronously, where anomalies are detected and later the detection results are retrieved. It provides accurate results over very large datasets. |
|
Sequential Probability Ratio Test (SPRT) |
A method that takes the estimates generated by MSET and compares them against the original signal value at a particular timestamp to decide whether the signal value is an anomaly. |
|
Intelligent Data Preprocessing (IDP) techniques |
A combination of different data preprocessing techniques to resolve different data quality issues from the data before training the model. IDP includes the 3 methods defined in the 3 rows. For example, ARP, MVI, and UNQ. |
|
Analytical Resampling Process (ARP) |
Used for aligning the signal values in a time series dataset with multiple signals that emit data that are not synchronized. Commonly used when clock out of sync problems exist. |
|
Missing Value Imputation (MVI) |
Used for deriving the missing sensor data in a dataset. Commonly used when signals are not reported because of component failures. |
|
UnQuantization (UnQ) |
Used for improving the quality of low-resolution input signals to a higher resolution. Commonly used in IoT applications where sensors send low-resolution signals. |
|
Asynchronous Inference |
Perform inferencing asynchronously, and then retrieve inferencing results. |
|
One Class Support Vector Machine (SVM) |
SVM \is a one-class classifier is used for detecting anomalies. When SVM is used for anomaly detection, it has the classification machine learning technique but no target. One Class Support Vector Machine (SVM) |
|
Asynchronous Detection |
Detection performed asynchronously, where anomalies are detected and later the detection results are retrieved. It provides accurate results over very large datasets. |
|
Synchronous Detection |
Detection performed synchronously, where anomalies are detected and the detection results are immediately retrieved. |
Regions and Availability Domains
OCI services are hosted in regions and availability domains. A region is a localized geographic area, and an availability domain is one or more data centers located in that region.
Anomaly Detection is hosted in these regions:
-
Australia East (Sydney)
-
Australia Southeast (Melbourne)
-
Brazil East (Sao Paulo)
-
Brazil Southeast (Vinhedo)
-
Canada Southeast (Montreal)
-
Canada Southeast (Toronto)
-
Chile Central (Santiago)
-
France Central (Paris)
-
France South (Marseille)
-
Germany Central (Frankfurt)
-
India South (Hyderabad)
-
India West (Mumbai)
-
Israel Central (Jerusalem)
-
Italy Northwest (Milan)
-
Japan Central (Osaka)
-
Japan East (Tokyo)
-
Mexico Central (Queretaro)
-
Netherlands Northwest (Amsterdam)
-
Saudi Arabia West (Jeddah)
-
Singapore (Singapore)
-
South Africa Central (Johannesburg)
-
South Korea Central (Seoul)
-
South Korea North (Chuncheon)
-
Spain Central (Madrid)
-
Sweden Central (Stockholm)
-
Switzerland North (Zurich)
-
UAE Central (Abu Dhabi)
-
UAE East (Dubai)
-
UK South (London)
-
US East (Ashburn)
-
US Midwest (Chicago)
-
US West (Phoenix)
-
US West (San Jose)
Resource Identifiers
The Anomaly Detection service supports private endpoints, data assets, models, and asynchronous jobs as OCI resources. Most types of resources have a unique, Oracle-assigned identifier called an Oracle Cloud ID (OCID). For information about the OCID format and other ways to identify your resources, see Resource Identifiers.
Ways to Access Oracle Cloud Infrastructure
You can access OCI using the Console (a browser-based interface), the command line interface (CLI), or the REST API. Instructions for the Console, CLI, and API are included in topics throughout this guide. For a list of available SDKs, see Software Development Kits and Command Line Interface.
To access the Console, you must use a supported browser. You can use the Console link at the top of this page to go to the sign-in page. You are prompted to enter your cloud tenant, your user name, and your password.
For general information about using the CLI, see Command Line Interface (CLI). For general information about using the API, see REST APIs.
Authentication and Authorization
Each service in OCI integrates with IAM for authentication and authorization, for all interfaces (the Console, SDK or CLI, and REST API).
An administrator in your organization needs to set up groups , compartments , and policies that control which users can access which services, which resources, and the type of access. For example, the policies control who can create new users, create and manage the cloud network, start instances, create buckets, download objects, and so on, see Getting Started with Policies.
- For details about writing Anomaly Detection policies, see Anomaly Detection Policies.
- For details about writing policies for other services, see Policy Reference.
If you’re a regular user (not an administrator) who needs to use the OCI resources that your company owns, contact your administrator to set up a user ID for you. The administrator can confirm which compartment or compartments you should be using.