Jobs
Data Science jobs enable custom tasks that you can apply any use case you have, such as data preparation, model training, hyperparameter tuning, batch inference, and so on.
Using jobs, you can:
-
Run machine learning (ML) or data science tasks outside of notebook sessions in JupyterLab.
-
Operationalize discrete data science and machine learning tasks as reusable runnable operations.
-
Automate typical MLOps or CI/CD pipeline.
-
Run batches or workloads triggered by events or actions.
-
Batch, mini batch, or distributed batch job inference.
-
Process batch workloads.
-
Bring your own container.
Typically, an ML and data science project is a series of steps including:
-
Access
-
Explore
-
Prepare
-
Model
-
Train
-
Validate
-
Deploy
-
Test
After the steps are completed, you can automate the process of data exploration, model training, deploying and testing using jobs. A single change in the data preparation or model training, experiments with hyperparameter tunings could be run as Job and independently tested.
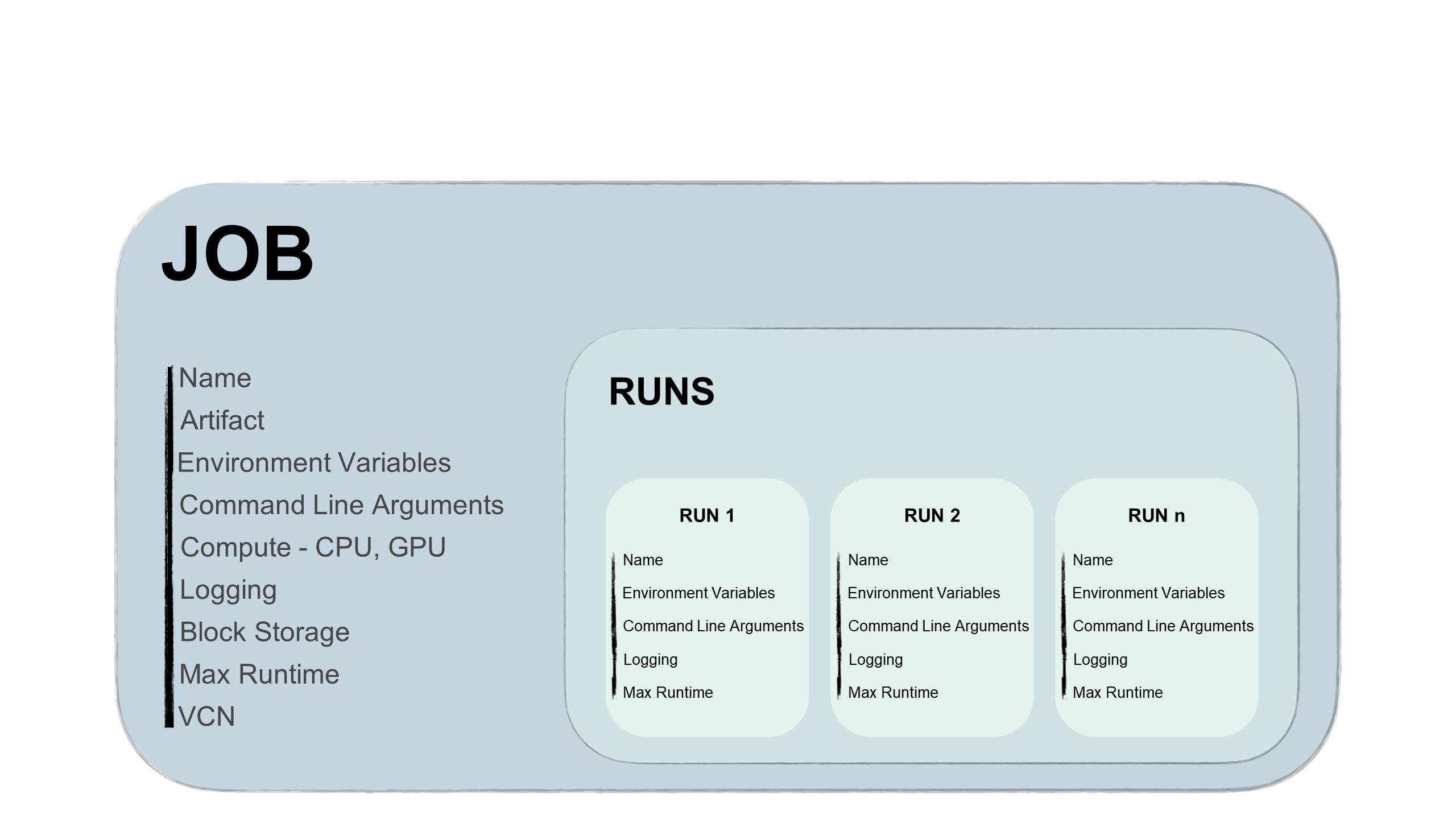
Jobs are two parts, a job and a job run:
- Job
-
A job is template that describes the task. It contains elements such as the job artifact that's immutable and can't be changed after it's uploaded to a job. Also, the job contains information about the Compute shapes the job runs on, logging options, block storage, and other options. You can add environment variables or CLI arguments to jobs to be unique or similar for all future job runs. You can override these variables and arguments in job runs.
You can edit the Compute shape in the job and between job runs. For example, if you notice that you want to run a job run on more powerful shape, you can edit the job Compute shape, and then start a new job run.
Tip
You don't need to wait for job run to finish to edit the shape.
- Job Run
-
A job run is the actual job processor. In each job run, you can override some job configuration options, and most importantly the environment variables and CLI arguments. You can have the same job with several sequentially or simultaneously started job runs with different parameters. For example, you could experiment with how the same model training process performs by providing different hyperparameters.
Jobs Lifecycle
Every stage of the job lifecycle triggers events that you can use to send notifications, trigger third-party functions, or even another job runs.
- Creating jobs
-
Job creation is when you create a job configuration including specifying a job artifact file. The job artifact contains the job executable code. This artifact can be Python, Bash/Shell, or a zip or compressed tar file containing an entire project written in Python or Java.
Also, you specify the Compute shape to run the job artifact, and the block storage and networking. You have the flexibility to select various CPU and GPU shapes, and a block storage up to 1 TB. The logging option allows you to set automatic logging creation for every job run.
Storage mounts can be used as follows:
- Store logs during model training that can be accessed from elsewhere.
- Store checkpoints during model training so that you can continue to train a model from the last checkpoint and avoid starting training from the beginning.
- Storing and reading data from common file system mount so you don't have to copy the data to the machine running the job.
- Starting job runs
-
This is the job processor. Starting a job run allows you to change some configured parameters to change the use case.
The job run uses several lifecycle operations. For a job run, the Data Science service handles provisioning the infrastructure, running the job artifact, and deprovisioning the infrastructure when job artifact run completes.
One job can have many job runs that can be run sequentially or simultaneously. You can configure a maximum runtime for the job run. When a job run remains in progress beyond the configured maximum runtime, the Data Science service automatically cancels the job run. We recommend that you configure a maximum runtime on all job runs to prevent runaway job runs.
Note
The upper limit for the maximum runtime is 30 days for a job run. If this value isn't configured, the 30 day limit is still enforced.
- Monitoring
-
During the job run, you can monitor the process by enabling logging with the Logging service. The messages are logged for the job run and the job artifact file.
Monitoring helps you debug for potential errors and monitor the resources used.
- Ending
-
A job run ends with the code process exit. It triggers the final lifecycle of the job run, which is the deprovisioning of the infrastructure. The infrastructure is destroyed also when you cancel a job run.
Jobs Access to Cloud Resources
Jobs can access to all OCI resources in a tenancy, as long as there's a policy to allow it. You can run jobs against data in ADW or Object Storage. Also, you can use vaults to provide secure way to authenticate against third-party resources. Jobs can access external sources if you have configured the appropriate VCN.
Job Runs Access
Job runs support the OCI SDK and API. You can run jobs from all possible outside third-party services from, for example:
- Your client machine, a MLOps, or CI/CD pipeline.
- GitHub or Bitbucket CI/CD pipelines.
- Oracle AI services or third-party.
- Events service.
You can create jobs and start job runs in the OCI Console, you can also create and run jobs with:
-
Python
-
Java
-
JavaScript
-
TypeScript
-
Go
-
Ruby
-
OCI CLI
-
Terraform