Model Deployment Autoscaling
Learn about autoscaling model deployment.
When setting up a model deployment, it's crucial to make decisions about the appropriate compute shape and the number of instances. Predicting the best scale for deployment can be challenging because of external variables. Balancing the need for constant availability and best performance against cost efficiency is a common dilemma, especially when dealing with unpredictable workloads.
Autoscaling offers a solution by letting you define a range for the number of instances, empowering the service to automatically scale up or down as demand fluctuates. This approach ensures efficient resource usage while accommodating increases in usage. You have the flexibility to set usage thresholds that trigger the scaling process, letting you control how quickly the deployment adapts to changes in demand.
Moreover, you can extend autoscaling capabilities to load balancers. By specifying a bandwidth range with minimum and maximum values, the load balancer adjusts automatically to varying traffic requests. This not only enhances performance, but also contributes to effective cost management by dynamically responding to changing workload demands.
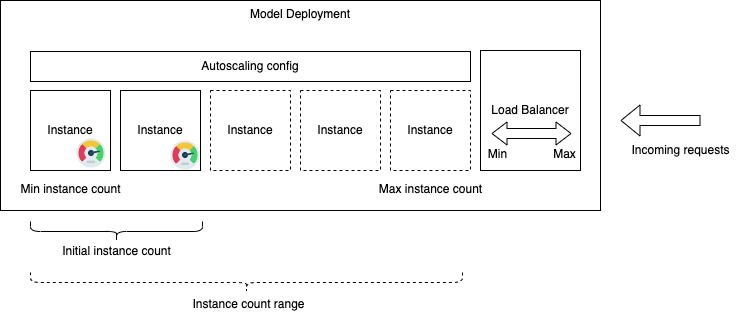
Some Key benefits of autoscaling for model deployment include:
-
Dynamic Resource Adjustment: Autoscaling automatically increases or decreases the number of compute resources based on real-time demand (for example, autoscale and downscale from 1 to 10). This ensures that the deployed model can handle varying loads efficiently.
-
Cost Efficiency: By adjusting resources dynamically, autoscaling ensures you only use (and pay for) the resources you need. This can result in cost savings compared to static deployments.
-
Enhanced Availability: Paired with a load balancer, autoscaling ensures that if one instance fails, traffic can be rerouted to healthy instances, ensuring uninterrupted service.
- Customizable Triggers: Users can customize the autoscaling query using MQL expressions.
- Load Balancer Compatibility: Autoscaling works hand-in-hand with load balancers where LB bandwidth can be scaled automatically to support more traffic, ensuring best performance and reducing bottlenecks.
- Cool-down Periods: After scaling actions, there can be a defined cool-down period during which the autoscaler doesn't take further actions. This prevents excessive scaling actions in a short time frame.
Types of Autoscaling Supported
Metric-based autoscaling is the supported method for autoscaling in a model deployment, wherein an autoscaling action is triggered when a performance metric meets or exceeds a defined threshold. At the moment, only one metric-based autoscaling policy can be added.
Metric-based autoscaling relies on performance metrics collected by the Monitoring service and emitted by the Model Deployment resource, such as CPU utilization. These metrics are aggregated into specified time periods and then averaged across all instances in the model deployment resource. When a set number of consecutive values (average metrics for a specified duration) meet the threshold, an autoscaling event is triggered.
A cool down period between metric-based autoscaling events lets the system stabilize at the updated level. The cool down period starts when the Model Deployment reaches the Active state. The service continues to evaluate performance metrics during the cool down period. When the cool down period ends, autoscaling adjusts the Model Deployment's size again if needs be.
You can configure metric-based autoscaling by selecting either:
-
PREDEFINED_EXPRESSION
-
CUSTOM_EXPRESSION
In the predefined type, choose one of the two metrics, CPU_UTILIZATION, or
MEMORY_UTILIZATION, and specify thresholds for the scaling conditions. In a
custom scaling metric type or expression, you have complete control over defining the scaling
conditions in the form of MQL and selecting any Model Deployment metric wanted.
Prerequisites
Before using autoscaling, add the following prerequisites.
Policies
allow service autoscaling to read metrics in tenancy where target.metrics.namespace='oci_datascience_modeldeploy'
Autoscaling in Action
As the model deployment resource undergoes scaling, monitor the work request (surfaced as Update Work Request) logs to track its progress.
The Update Work Request logs provide real-time updates on the ongoing operations, detailing what changes are being made, including the previous and new sizes.
In the event of a model deployment creation or update failure, select Error Messages on the left side menu to identify the specific error or failure reason. For guidance on resolving different error scenarios and steps to debug any issues, see the Troubleshooting section For Autoscaling Model Deployments.