Burstable Instances for Model Deployment
Data Science Model Deployment is a fully managed service to deploy trained Machine Learning models on inference web endpoints. The inference endpoints host ML model binaries as web-services for real-time consumption of predictions.
During the creation of the deployment, users need to decide which compute shape to use and how many instances. Often, it's difficult to decide in advance what scale the model deployment requires, because it depends on external factors. From one side, you want to have the model available always for inferencing in its best performance, on the other side, you want to optimize costs and not have compute create instances that aren't required.
With support for Burstable VMs, you can enable deployments to use fractions of VM cores, to optimize compute usage even further, when models require only a small amount of compute to operate and the request load is low.
Key Features
- Burstable Instances for Machine Learning: Lets deployment of machine learning models on virtual machines with flexible CPU usage.
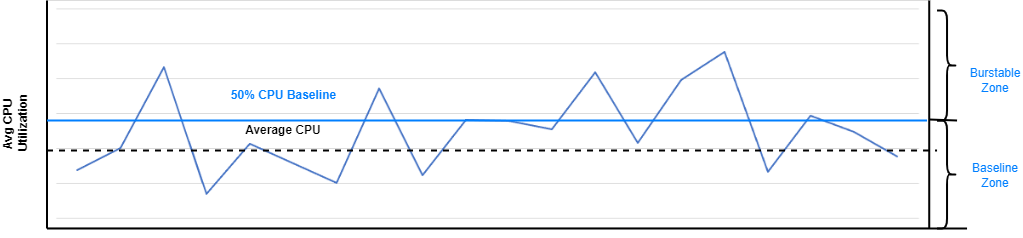
- Baseline CPU Utilization: OCI offers less than a typical CPU baseline suitable for varying workload demands. The options are 50% or 12.5%, so suitable for varying workload demands. If you deploy machine learning models, only the 50% baseline is available.
- Surge Capability: Can surge to higher levels during occasional spikes in server requests, adapting to changing computational needs.
- Comparison to Traditional VMs: Unlike traditional VM instances with fixed CPU resources, burstable instances maintain a standard CPU utilization level.
- User-Selected Baseline and Bursting: Lets users to select a baseline CPU utilization, with the capability to momentarily increase CPU usage above this baseline, up to 100% of the provisioned CPU cores.
Billing
Burstable instances are billed according to the baseline OCPU selected when creating or updating a model deployment. The charge for a burstable instance is the same regardless of whether the actual CPU utilization is at the baseline, less than the baseline, or bursts more than the baseline.
For example, if you create a deployment with VM.Standard.E4.Flex instance using 1 OCPU and a 50% baseline, you're charged for 50% of a Standard E4 OCPU each hour, regardless of whether the actual CPU utilization is under 50% of an OCPU or bursts to the full OCPU.
For more information, see the Burstable Instances documentation.
Supported Shapes
Specific shapes are supported for burstable model deployments.
For supported shapes, see the Compute documentation.
Current Limitations
These are the limitations of burstable VM model deployments.
- Only 50% baseline is supported with a minimum of 6 GB memory, the baseline of 12.5% isn't supported.
- The burst is limited to a maximum one hour continuous burst
- Memory doesn't burst.
- If the underlying host is oversubscribed, it's not guaranteed that an instance can burst exactly when needed.