Using Notebooks to Connect to Data Flow
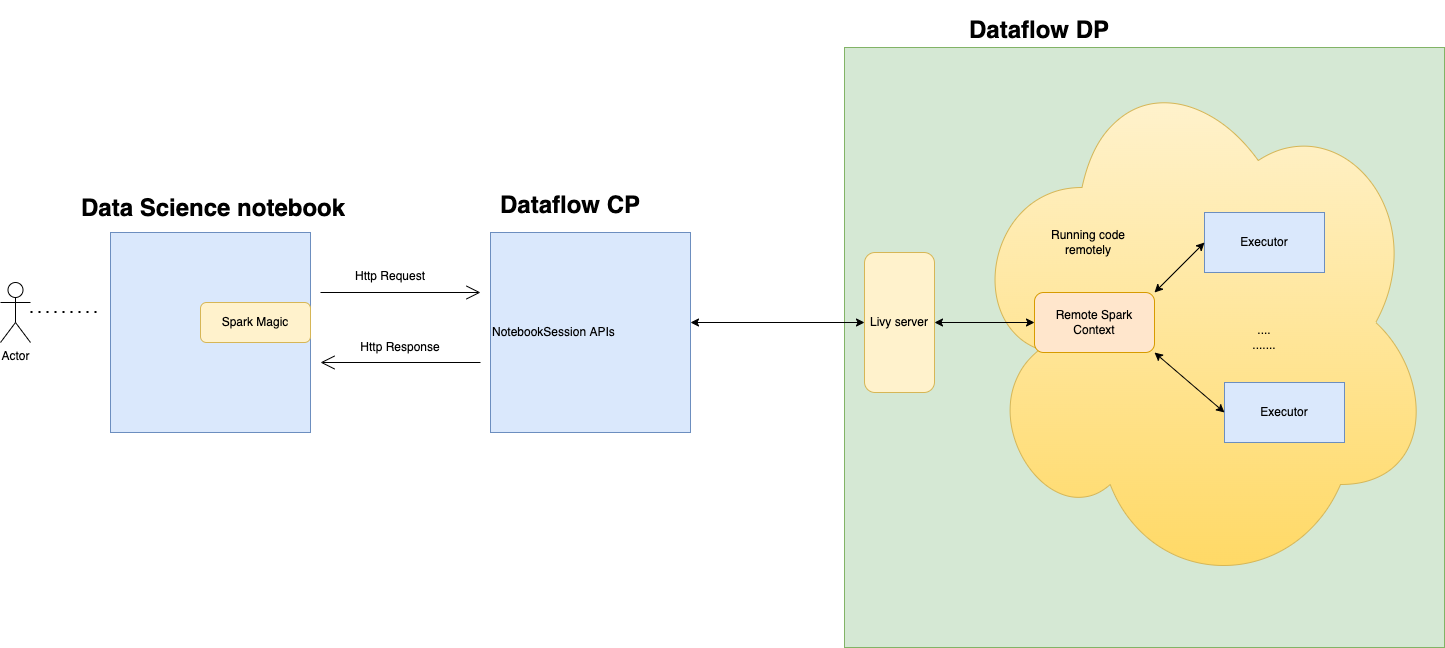
You can connect to Data Flow and run an Apache Spark application from a Data Science notebook session. These sessions let you run interactive Spark workloads on a long lasting Data Flow cluster through an Apache Livy integration.
Data Flow uses fully managed Jupyter Notebooks to enable data scientists and data engineers to create, visualize, collaborate, and debug data engineering and data science applications. You can write these applications in Python, Scala, and PySpark. You can also connect a Data Science notebook session to Data Flow to run applications. The Data Flow kernels and applications run on Oracle Cloud Infrastructure Data Flow. Data Flow is a fully managed Apache Spark service that performs processing tasks on extremely large datasets, without the need to deploy or manage infrastructure. For more information, see the Data Flow documentation.
Apache Spark is a distributed compute system designed to process data at scale. It supports large-scale SQL, batch, and stream processing, and machine learning tasks. Spark SQL provides database-like support. To query structured data, use Spark SQL. It is an ANSI standard SQL implementation.
Data Flow is a fully managed Apache Spark service that performs processing tasks on extremely large datasets, without infrastructure to deploy or manage. You can use Spark Streaming to perform cloud ETL on your continuously produced streaming data. It enables rapid application delivery because you can focus on application development, not infrastructure management.
Apache Livy is a REST interface to Spark. Submit fault-tolerant Spark jobs from the notebook using synchronous and asynchronous methods to retrieve the output.
SparkMagic allows for interactive communication with Spark
using Livy. Using the `%%spark` magic directive within a JupyterLab
code cell. The SparkMagic commands are avilable for Spark 3.2.1 and the Data Flow conda environment.
Data Flow Sessions support auto-scaling Data Flow cluster capabilities. For more information, see Autoscaling in the Data Flow documentation. Data Flow Sessions support the use of conda environments as customizable Spark runtime environments.
- Limitations
-
-
Data Flow Sessions last up to 7 days or 10,080 mins (maxDurationInMinutes).
- Data Flow Sessions have a default idle timeout value of 480 mins (8 hours) (idleTimeoutInMinutes). You can configure a different value.
- The Data Flow Session is only available through a Data Science Notebook Session.
- Only Spark version 3.2.1 is supported.
-
Watch the tutorial video on using Data Science with Data Flow. Also see the Oracle Accelerated Data Science SDK documentation for more information on integrating Data Science and Data Flow.